
MySQL-Cluster
클러스터 설명
MySQL Replication은 확장의 제약을 가진다. 왜냐하면 데이터 입력 및 업데이트가 master 서버에 의존적이기 때문에 시스템 확장 시 slave 서버의 증설은 용이하지만 master 서버의 증설에는 어느 정도 제약이 따르게 된다. 하지만 MySQL Cluster는 데이터 입/출력을 모두 처리하는 형태로 구현되기 때문에 어떠한 특정 DB 서버에 의존적이지 않다.
클러스터의 장점
- 파이브 나인의 고가용성 시스템 구축과 운영이 가능하다.
- 메인 메모리 또는 하드디스크 기반의 고성능 데이터베이스 구현이 가능하다.
- 매우 빠르고 자동적인 FailOver 시스템을 가지고 있다.
- 유동적이고 병렬적인 분배 구조 시스템을 가지고 있다.
- 별도의 라이선스 및 제반 비용이 필요 없는 저렴한 구축비와 유지비가 장점이다.
클러스터의 단점
- 병목현상
- 서버 전환시 짧은 시간 동안 서비스 이용 불가
클러스터 구성하기
먼저 MySQL 클러스터를 구성하기 위해서는 최소 3대 이상의 서버가 필요하다.
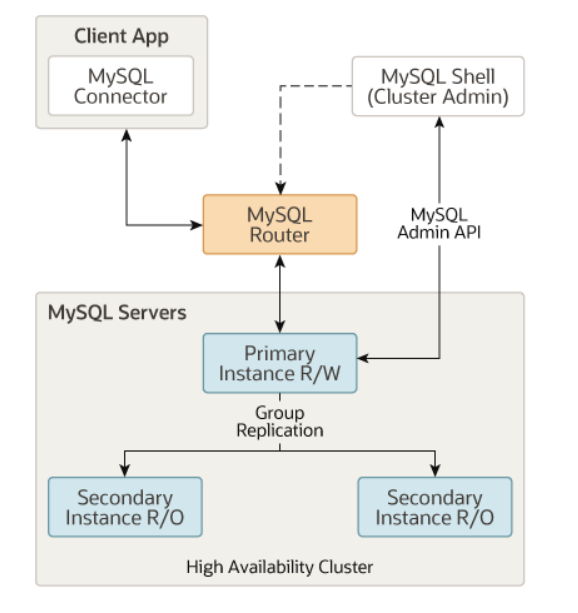
현재 사용하고 있는 InnoDB 엔진의 클러스터를 살펴보면 먼저 MySQL Shell이라는 클라이언트 프로그램을 통해서 클러스터를 생성하게 되고 MySQL 서버 집합을 활성화하기 위한 복제 작업이 진행된다.
복제가 완료된 후 MySQL Router를 통해서 애플리케이션(워크벤치)과 InnoDB 클러스터 간의 라우팅을 제공하게 된다.
해당 작업들이 어떻게 이루어지는지 직접 개발해 보면서 하나씩 살펴보자.
먼저 IP 설정과 방화벽 설정을 진행한다.
현재 가상 머신 서버 구성
- 12.12.12.10 db1
- 12.12.12.20 db2
- 12.12.12.30 db3
- 12.12.12.100 router
IP 주소마다 각 서버의 이름을 vi 편집기를 통해서 /etc/hostname을 설정해 준다.
설정이 완료된 후 vi 편집기를 통해서 /etc/hosts를 편집하여 위의 4가지 주소를 설정해 준다.
host 설정이 다 완료된 후 재시작을 먼저 진행한다. 그 후 DB로 사용할 서버마다 mysql-server를 설치해 준다.(총 3대)
mysql 서버가 설치 완료되고 난 후 mysql-shell을 설치해 준다.
MySQL :: MySQL Shell 8.0 :: 2.2 Installing MySQL Shell on Linux
2.2 Installing MySQL Shell on Linux Note Installation packages for MySQL Shell are available only for a limited number of Linux distributions, and only for 64-bit systems. For supported Linux distributions, the easiest way to install MySQL Shell on Linux
dev.mysql.com
설치가 완료된 이후 mysql 서버를 실행시키고 초기 설정을 진행해 준다. (나머지 DB 서버도 동일)
먼저 db1 서버에서 mysqlsh 명령어를 통해 shell을 실행시켜 준다.

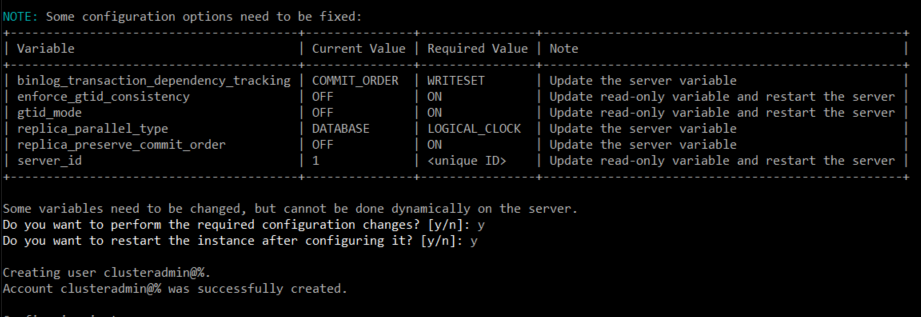
dba.configureInstance('사용자@IP주소:포트번호')
1. 클러스터를 생성하는 사용자의 비밀번호 설정
2. 설정한 비밀번호 확인
3. 새로운 계정을 생성할 것인지, 아니면 클러스터를 생성한 계정과 똑같이 만들 것인지
4. 새로 생성한 계정의 이름
5. 계정의 비밀번호
6. 비밀번호 확인
7. 위에서 설정한 것과 같이 설정을 바꿀 것인지
8. 설정이 완료된 후 재시작을 할 것인지
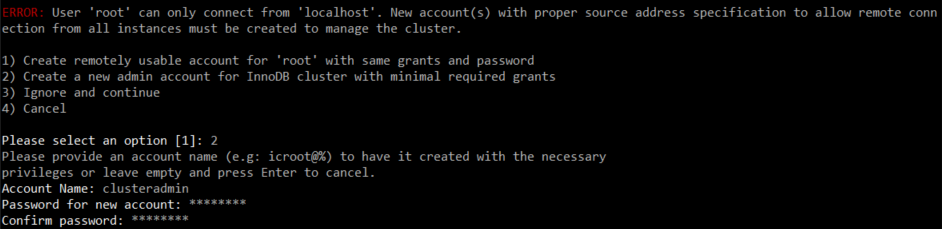
shell에 접속한 후, 먼저 클러스터를 구성하기 위한 계정을 생성한다.
clusteradmin이라는 계정을 새로 생성해 주고 관련 설정까지 완료한다.
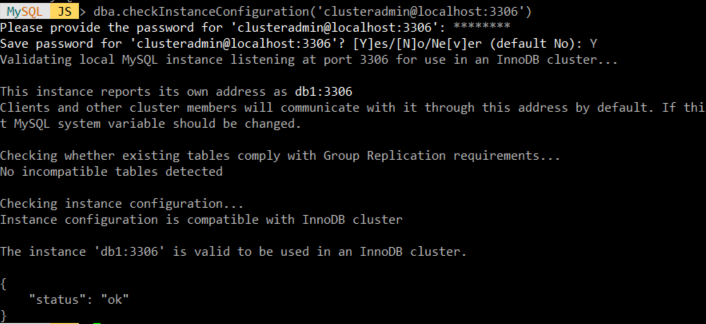
dba.checkInstanceConfiguration('생성한 계정이름@IP주소:포트번호')
계정을 생성한 후 root 계정으로 로그인해서 위에서 설정한 내용을 확인한다. (status가 ok인지 확인)
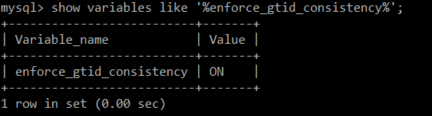
설정을 확인했으면 shell에서 나와 다시 mysql로 접속해 준다.
접속한 후 enforce_gtid_consistency가 ON인지 확인하고 나머지 db2, db3도 똑같은 설정을 진행한다.
enforce_gtid_consistency가 뭐지?
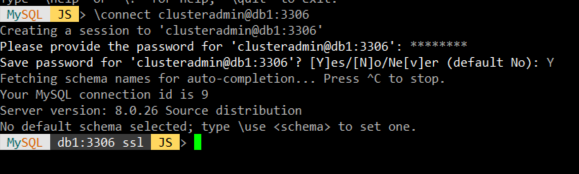
모든 db 서버의 설정이 완료되었으면, 먼저 db1의 clusteradmin 계정으로 접속한다.
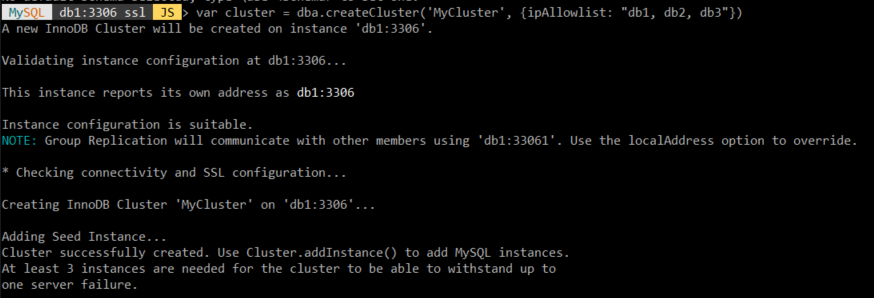
dba.createCluster('클러스터 이름', {ipAllowlit: "db서버 IP주소 설정한 이름"})
접속 후 새로운 클러스터를 생성한다. 이때 조심할 점으로는 현재 db1에서 설정한 host의 이름들이 다른 db서버도 마찬가지로 똑같이 설정이 되어있어야 한다.
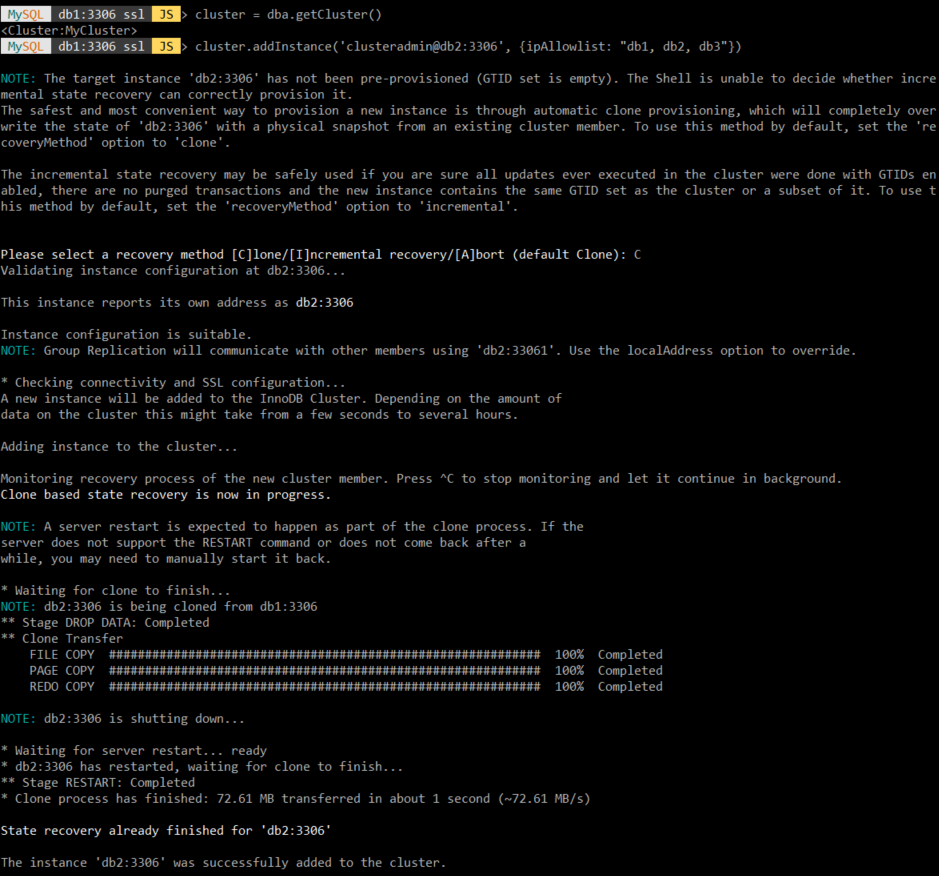
클러스터 생성이 완료되면 다른 DB서버인 db2와 db3도 클러스터에 추가해 준다. 이때 클론 방식으로 데이터를 공유하기 때문에 C를 입력해 준다.
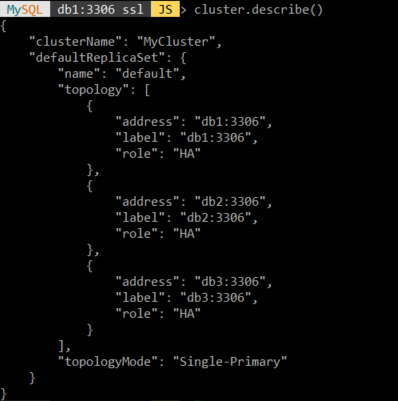
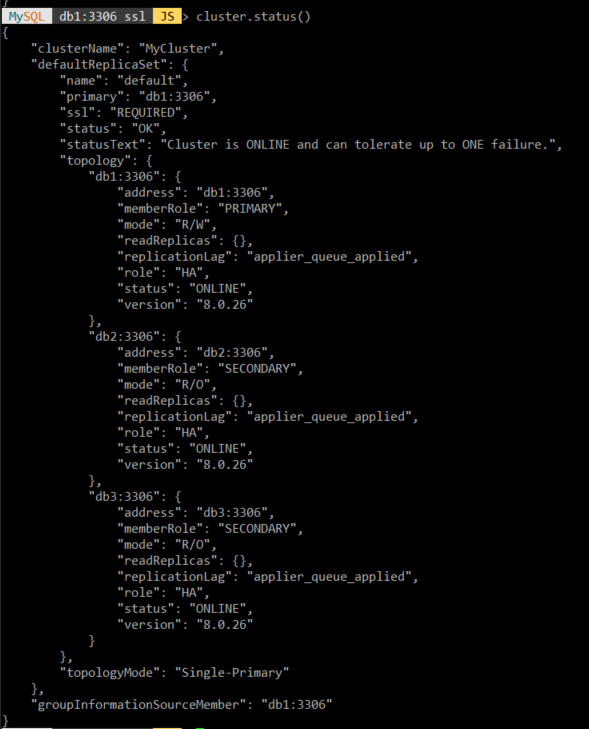
클러스터 생성이 완료된 후, 클러스터 상태를 확인해 본다.
중점적으로 확인해봐야 할 점들은 먼저 주소가 잘 설정되어 있는지 확인하고, 각 db 서버마다 memberRole이 어떻게 설정되어 있는지와 topologyMode가 어떻게 설정되어 있는지 확인해야 한다.
MySQL - Router
MySQL에서 클러스터를 구성하기 위해서는 라우터가 필요하다.
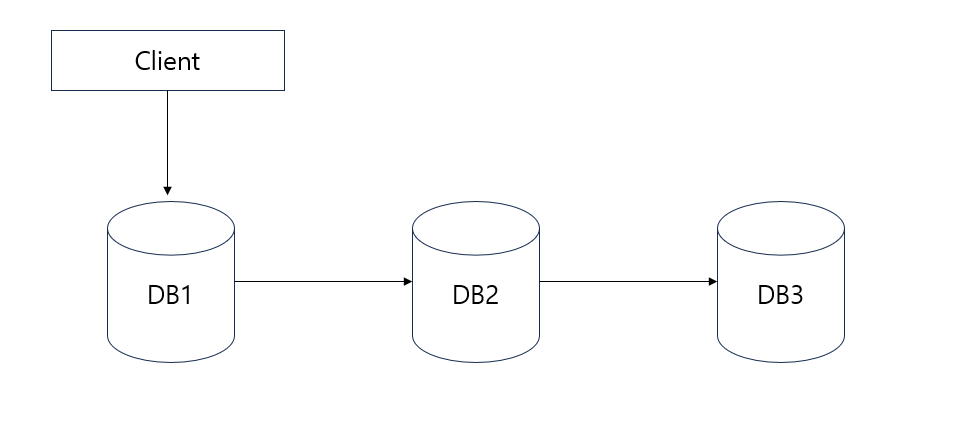
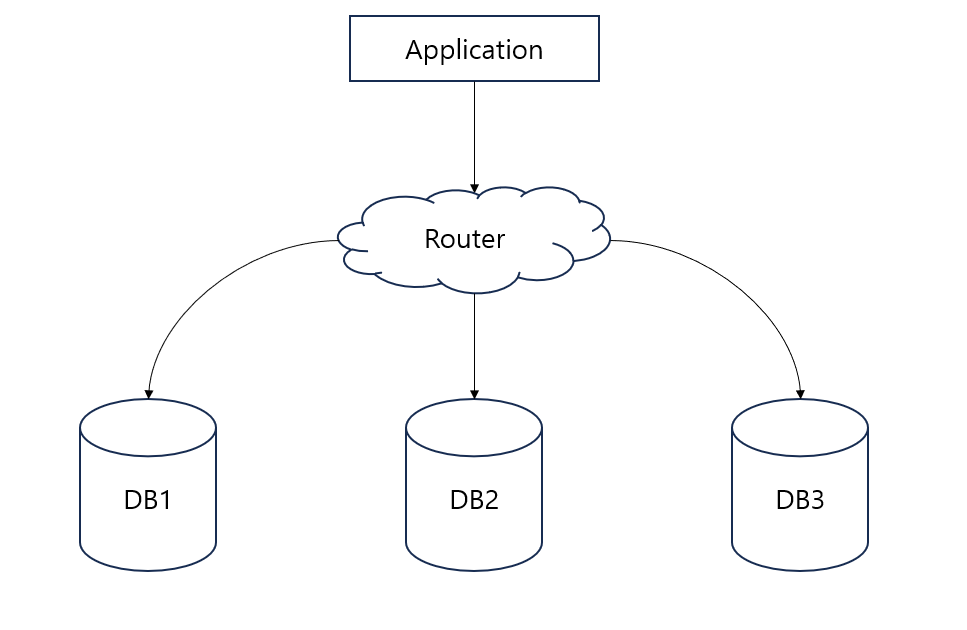
우리의 서버 구성이 위의 사진과 같이 되어 있다고 생각해 보자.
Client가 DB1으로만 접속을 하게 된다면 만약 DB1 서버가 다운되었을 때 자동으로 DB2 서버로 변경되는 것이 아니라 계속 DB1 서버로 접속을 시도하게 된다. 이러한 구성은 HA(고가용성) 기능이 제대로 작동하지 않게 되는 문제가 발생한다.
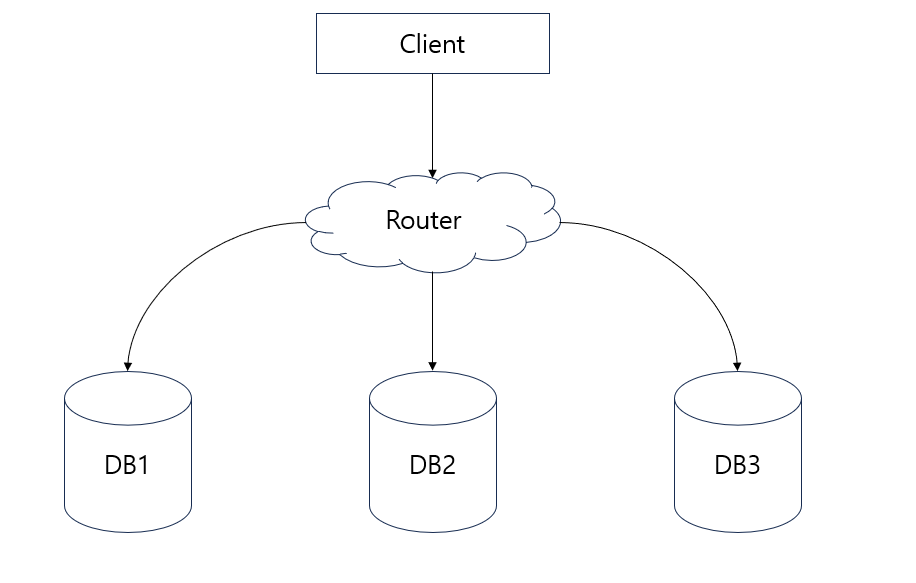
하지만, 클라이언트가 라우터와 접속하게 된다면 해당 라우터가 자동으로 로드밸런싱을 해주게 되고 DB1 서버가 다운될 시에 DB2, DB3 서버로 연결해 주기 때문에 클러스터를 구성하는 데 있어서 라우터까지 포함되어야 한다.
MySQL-Router 사용 방법
라우터를 설치하기 전에 먼저 IP 주소 설정을 진행한다.
설정이 완료되었으면 호스트 이름을 변경해 준다.
vi /etc/hostname # 현재 호스트의 이름
vi /etc/hosts # 다른 서버 호스트들의 이름
호스트 설정까지 완료했으면 재시작을 진행하여 설정한 내용을 확인한다. (네트워크 주소 및 호스트 네임 확인)


MySQL :: MySQL Router 8.0 :: 2.1 Installing MySQL Router on Linux
2.1 Installing MySQL Router on Linux There are binary distributions of MySQL Router available for several variants of Linux, including Fedora, Oracle Linux, Red Hat, and Ubuntu. Installation options include: Official MySQL Yum or APT repository packages:
dev.mysql.com
확인이 끝났으면 mysql-router를 설치해 준다.

--bootstrap: MySQL InnoDB 클러스터와 함께 작동하도록 부트스트랩 및 구성
--name: 라우터 인스턴스 이름
--directory: MySQL 라우터 인스턴스를 생성할 디렉터리
--account: MySQL 워크벤치에서 사용될 사용자 이름
--user: 기본 사용자 이름
계정@주소: InnoDB Cluster 멤버 중에서 Primary 역할을 하는 인스턴스 정보
라우터 설치가 완료되면 위의 몇 가지 옵션을 추가하여 라우터를 배포해 준다.

라우터 배포가 완료되면 앞서 설정한 mycluster 디렉터리가 생성되고, 해당 디렉터리로 이동하면 start.sh 파일을 확인할 수 있다.
이제 start.sh 파일을 실행하고 MySQL 워크벤치에 접속하면 정상적으로 접속이 되고 내가 구성한 MySQL Cluster 서버들을 확인할 수 있게 된다.
Cluster의 특성
클러스터는 Replication 구성과는 다르게 최소 3대 이상의 서버를 준비해야 되는데 만약 서버를 추가로 늘릴 시에 홀수를 맞춰야 한다.
그렇다면 왜 홀수로 구성을 해야 될까?
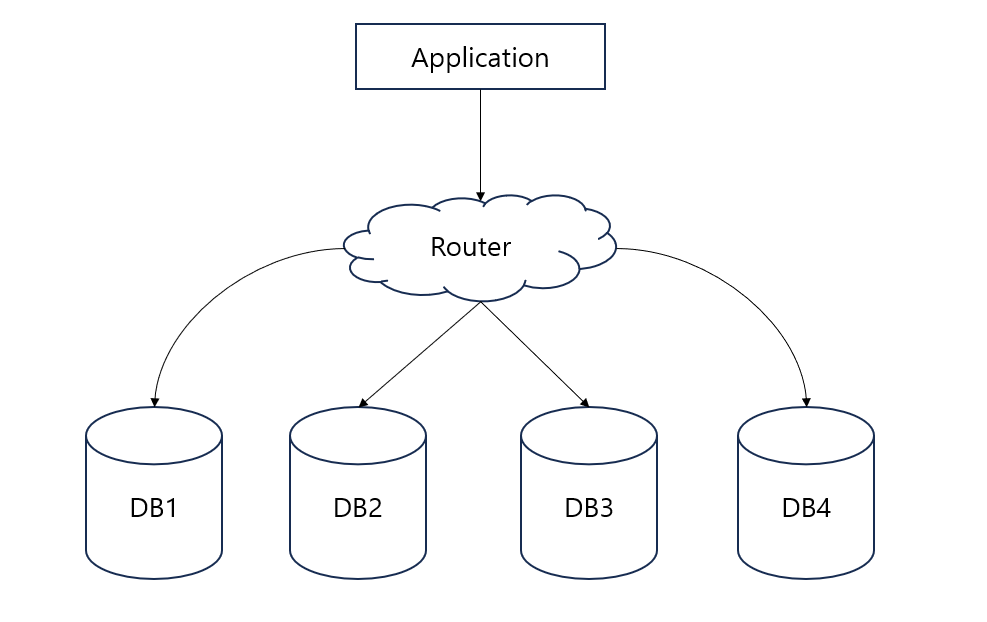
만약 개발한 서비스가 그림과 같이 4대의 DB 서버로 구성되어 있다고 가정해 보자.
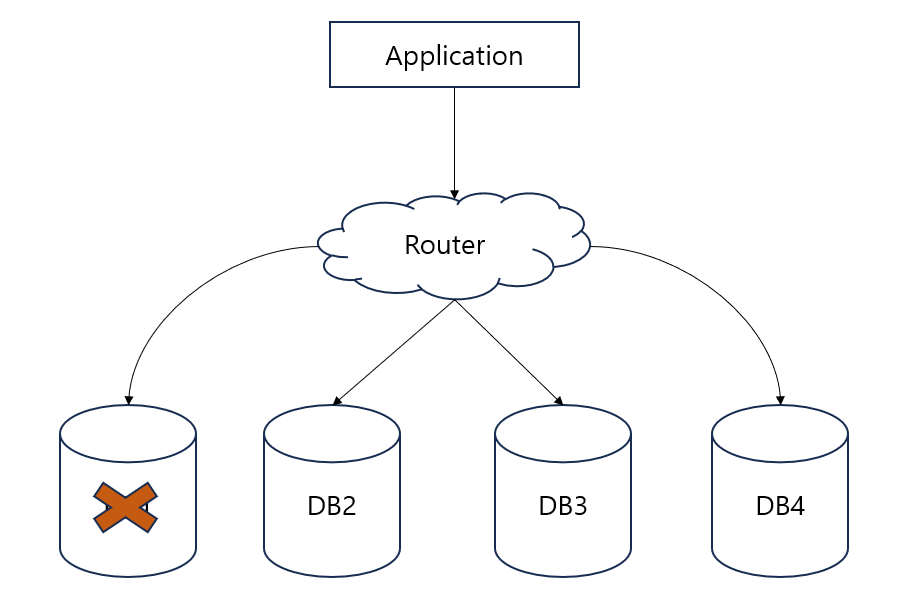
위의 그림과 같이 DB1 서버가 다운되었다고 생각해 보면 나머지 3대의 서버 중에서 마스터를 선정해야 한다.
마스터를 선정할 때 나머지 서버에서 투표를 진행하게 되는데 DB2 서버를 마스터로 선정하기 위해서는 DB3와 DB4가 투표를 진행한다.
하지만 문제는 여기서 발생하게 되는데 과반수 이상 투표가 이루어져야 DB2 서버를 마스터로 정할 수 있지만 남은 서버가 짝수로 되어있을 경우 과반수가 될 수 없다는 문제가 발생한다.
이러한 문제를 해결하기 위해 클러스터를 구성할 때는 서버를 홀수로 구성해야 된다.
투표라는 개념이 무슨 개념인지 이해가 안 되었는데 이러한 작동 방식을 클러스터 쿼럼 작동 방식이라고 한다는 것을 알게 되어 찾아보고 난 뒤에 이해할 수 있었다.
Azure Stack HCI 및 Windows Server 클러스터의 클러스터 및 풀 쿼럼 이해 - Azure Stack HCI
Azure Stack HCI 및 Windows Server 클러스터의 저장소 공간 다이렉트 클러스터 및 풀 쿼럼을 이해합니다. 특정 예제를 사용하여 복잡성을 살펴보겠습니다.
learn.microsoft.com
해당 링크를 들어가서 보면 클러스터 서버를 짝수로 구성하는 방법도 나와있으니 참고하면 좋을 것 같다.
# 테스트 1. Singlemode에서 primary DB서버 다운시키기
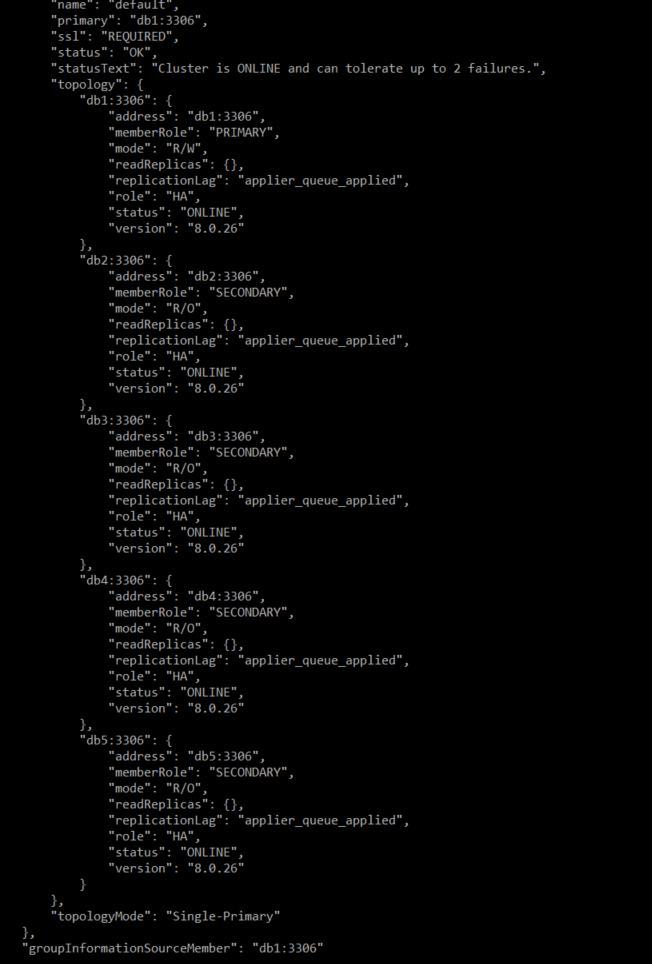
1번 디비를 다운시켰을 때
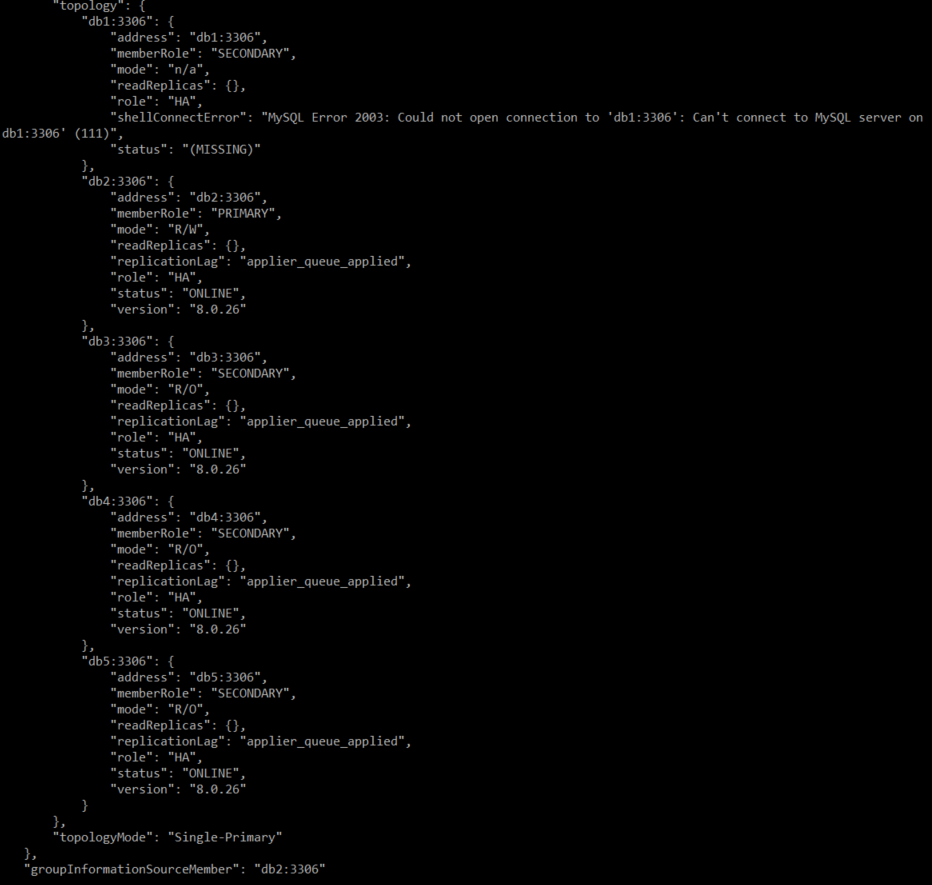
2번 디비를 다운시켰을 때
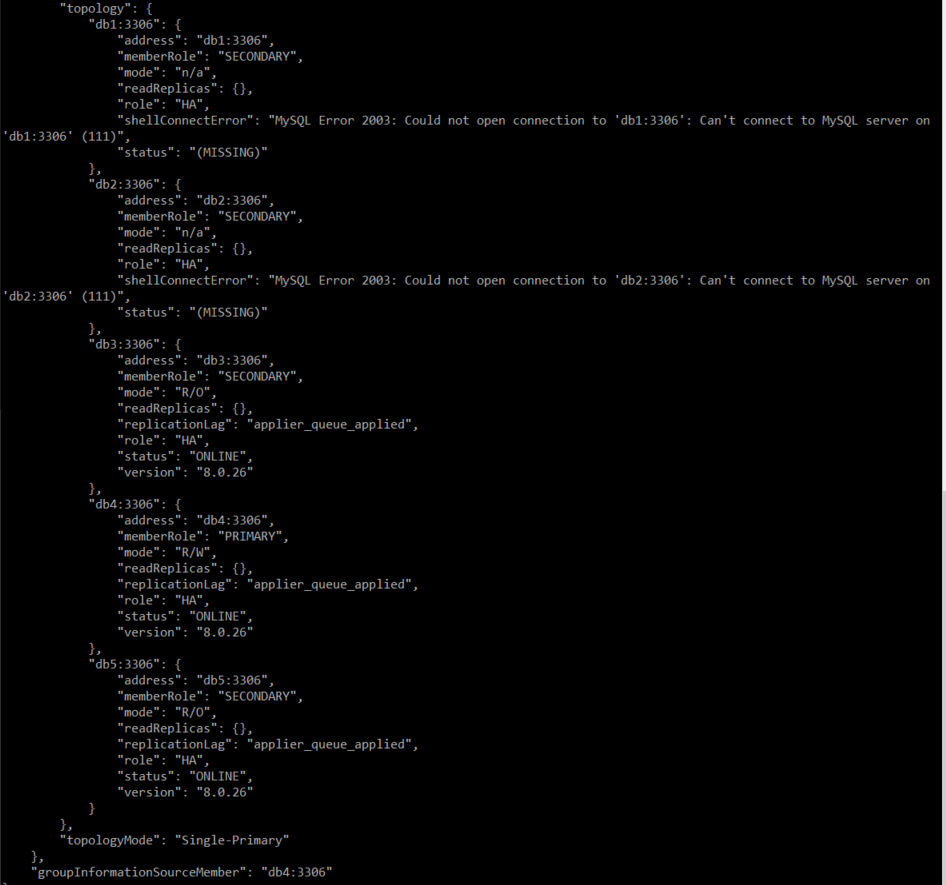
# 테스트 2. 멀티 프라이머리 모드로 전환해서 확인하기
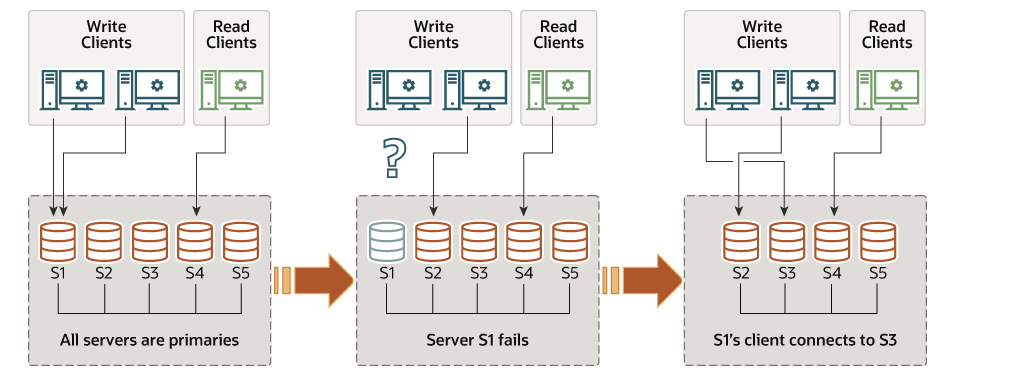
멀티 프라이머리 모드(다중 기본 모드)는 그룹 구성원에게 특별한 역할이 주어지지 않는다. 따라서 클라이언트 혹은 애플리케이션의 어느 멤버에게도 쓰기 트랜잭션을 요청할 수 있고 그룹은 해당 트랜잭션을 처리할 수 있다.
위의 사진과 같이 모든 서버들이 프라이머리 모드이기 때문에 서버가 다운되면 바로 다른 서버로 접속할 수 있게 된다.
밑에서 예제를 통해 확인해 보자.
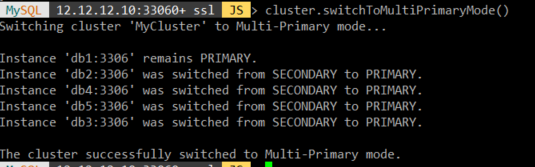
먼저 기존의 Sigle-Primary 모드에서 Mulity-Primary 모드로 스위칭을 진행한다.
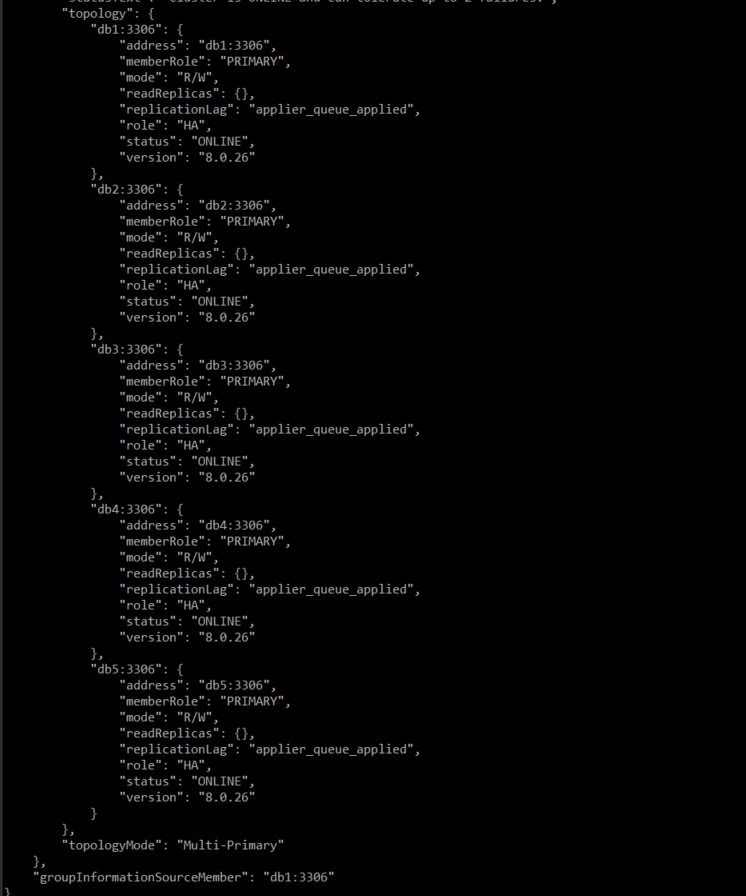
설정을 완료한 후 상태를 확인해 보면 모든 서버가 Primary 모드로 바뀐 것을 확인할 수 있다.
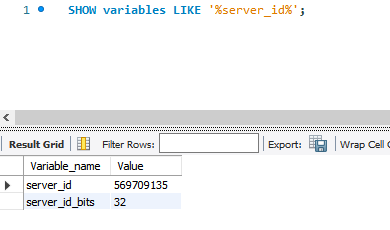
mysql 워크벤치로 접속하여 서버 아이디를 확인해 보면 6446 포트의 서버 아이디는 현재 db1 서버의 아이디로 설정되어 있다.
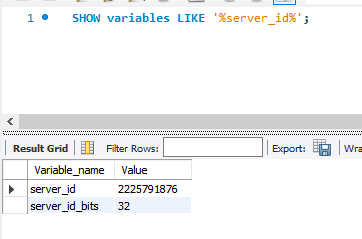
mysql 라우터의 6447 포트로 접속하면 서버 아이디가 바뀌어 있는데 접속을 시도할 때마다 바뀐다.
왜??
그럼 이제 db1의 mysql 서버를 종료하고 다시 확인해 보자.
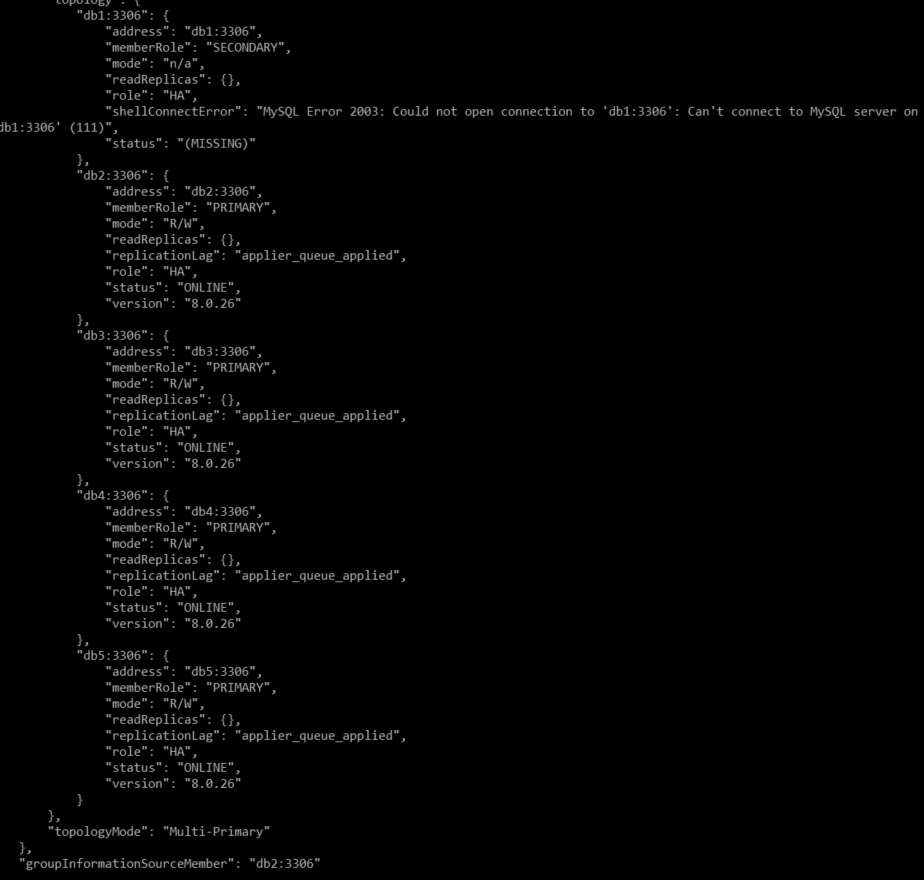
db서버 종료 후 db2의 clusteradmin 계정으로 접속하여 클러스터 상태를 확인해 보면 종료한 db1은 SECONDARY로 바뀌어 있고, 나머지는 Primary로 되어있다.
여기서 groupInformationSourceMember가 db2로 바뀐 것을 확인할 수 있는데 해당 속성은 그룹 정보를 제공하는 서버가 db2라는 것을 의미한다.
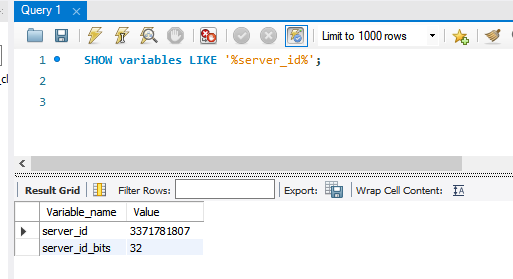
mysql 워크벤치 6446 포트로 접속하여 서버 아이디를 확인해 보면 기존의 db1에서 db2의 서버 아이디 주소로 바뀐 것을 확인할 수 있다.
Cluster와 Replication의 비교
| 번호 | Cluster | Replication |
| 1 | 단순히 DB 서버를 확장 | DB 서버 확장 및 스토리지도 확장 |
| 2 | 자동으로 FailOver 해주는 기능이 있다. | FailOver 해주는 솔루션을 따로 설치해야 한다. |
| 3 | 최소 3대 이상의 인스턴스가 필요 | 최소 2대 이상의 인스턴스가 필요 |
| 4 | 관리가 복잡해서 관리 작업 수행 시 운영자의 실수가 발생할 가능성이 높다. | 관리가 상대적으로 간단하여 관리 작업 수행 시 운영자의 실수가 발생할 가능성이 상대적으로 적다. |
| 5 | ||
| 6 | ||
| 7 |
'DB' 카테고리의 다른 글
| Redis - Redis 기초 (0) | 2023.11.18 |
|---|---|
| Mysql - Replication (1) | 2023.11.13 |
| 데이터베이스 - DB 이중화 (0) | 2023.11.12 |
| MySQL - View & Index (0) | 2023.11.11 |
| 데이터베이스 - 인덱스 (0) | 2023.11.10 |