
DB 설계하기
본격적인 개발을 시작하기에 앞서 DB를 먼저 설계해보려고 한다. DB는 RDBMS 계열의 MySQL을 선택했다.
ERD 그리기
이전 포스팅에서 언급했던 것처럼 회원, 게시판, 댓글 기능에 대해서 테이블을 생성하려고 한다.
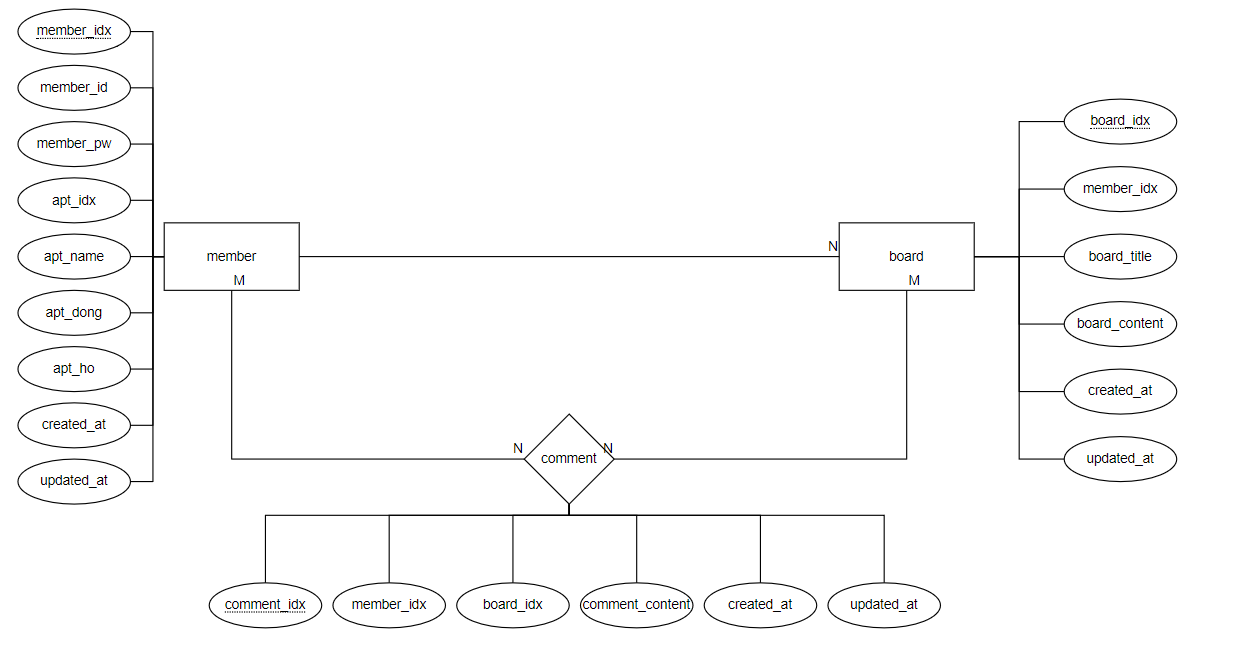
먼저 ERD를 그려보면 위의 그림과 같이 표현할 수 있다.
회원은 여러 게시판에 댓글을 작성할 수 있고, 게시판도 여러 회원을 통해서 댓글이 달릴 수 있다. 따라서 다 대 다 관계가 형성되면서 comment(댓글) 테이블로 분리하게 되었다.
ERD를 그려봤으니 이제 테이블 형태로 살펴보자.
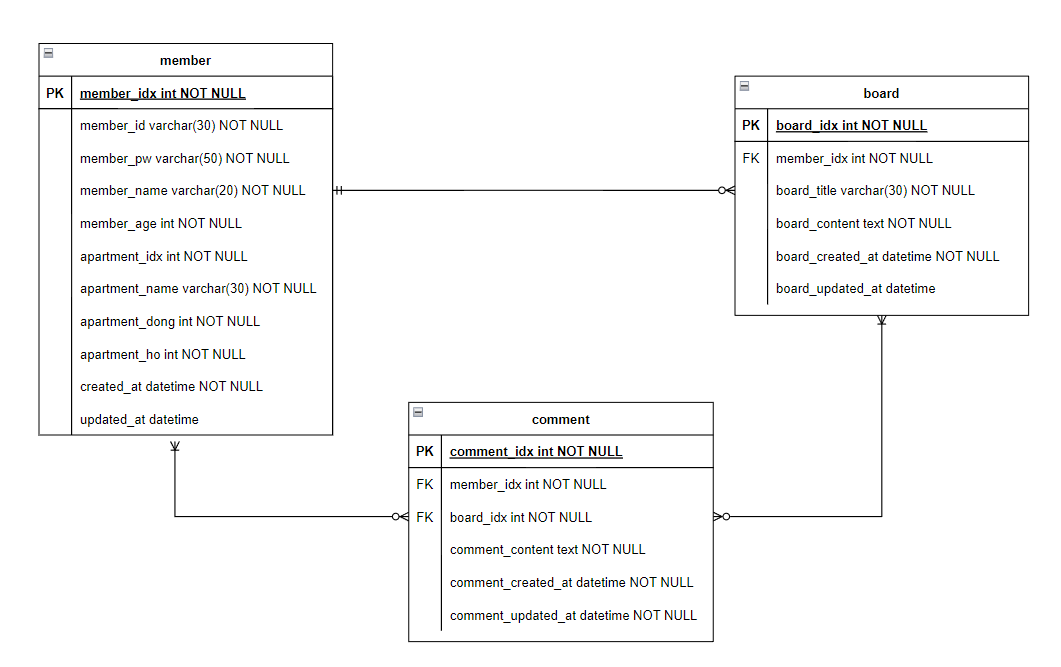
테이블로 표현하면 위의 그림과 같이 만들 수 있다. 각 테이블과 연관관계를 아래와 같이 정리해 보았다.
- 한 명의 회원은 여러 개의 게시글을 만들 수 있지만, 하나의 게시글은 오직 한 명에 의해서만 생성될 수 있다.
- 한 명의 회원은 여러 개의 게시글에 댓글을 남길 수 있다. 또한, 하나의 게시글에는 여러 명의 회원들이 댓글을 남길 수 있다.
정규화 진행하기
ERD까지 다 그린 뒤 정규화를 진행해 보았다.

먼저 회원 테이블에 대해서 스키마를 작성해 보면 위의 그림과 같이 만들 수 있다.
[DB] - 정규화
함수 종속(Functional Dependency)정규화를 알아보기 전에 먼저 함수 종속을 알아야 한다. 함수 종속(FD)이란 한 테이블에 있는 두 개의 속성 집합 사이의 제약을 의미한다.만약 특정 X 값에 따라서 Y 값
hotechstory.tistory.com
이전에 정규화를 정리해 보면서 공부했던 것을 프로젝트에 적용해 볼 예정이다. 따라서 먼저 키와 함수 종속(FD)을 파악해 보자.
현재 member 테이블에서 키를 확인해 보면 기본키로 member_idx가 있고, 후보키로는 {member_id}, {member_id, apt_idx} 이 정도 있을 것 같다.
prime-attribute는 member_idx, member_id, member_name, apt_idx가 있고,
non-prime-attribute로는 member_pw, member_age, apt_name, apt_dong, apt_ho, created_at, updated_at이 있다.
알아본 키를 통해서 함수 종속을 찾아보면 아래와 같이 나올 수 있다.
{member_idx} -> {member_id, member_pw, member_name, member_age, created_at, updated_at}
{member_id} -> {member_idx, member_pw, member_name, member_age, created_at, updated_at}
{member_id, apt_idx} -> {member_idx, member_pw, member_name, member_age, apt_name, apt_dong, apt_ho created_at, updated_at}
정규화를 진행해 보면 먼저 1NF에 걸리는 부분은 없으니 바로 2NF로 넘어간다.
현재 non-prime-attribute는 {member_id, apt_idx}에 대해서 부분 함수 종속인 것을 알 수 있다. 왜냐하면 apt_idx만으로도 non-prime-attribute를 결정할 수 있기 때문에 이 부분을 제거하여 완전 함수 종속이 되게 만들어야 한다.
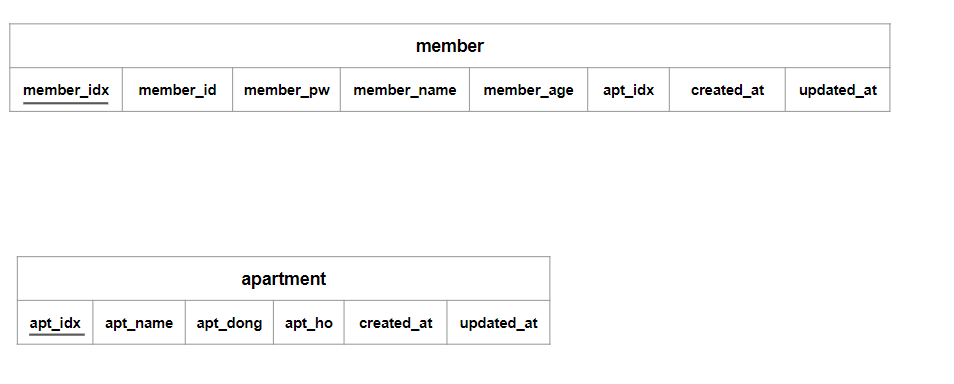
2NF를 진행하게 되면 위의 그림과 같이 테이블이 분리가 된다. 그다음으로 3NF를 진행해야 하지만 3NF의 규칙이 되는 이행적 함수 종속이 없기 때문에 정규화는 종료된다.

최종적으로 정규화된 스키마를 다시 ERD로 그려보았다.
새롭게 apartment라는 테이블이 생성되면서 기존의 member 테이블과 관계를 맺어주었고, member 테이블에서 apt_idx를 외래키로 지정해 주었다.
varchar와 text 타입의 차이
테이블을 설계하면서 한 가지 의문점이 있었는데 바로 varchar와 text 타입의 차이점이었다.
varchar는 길이를 지정해서 사용할 수 있고, text는 따로 지정 없이 사용할 수 있다 정도로만 알고 있었는데 정확히 어떤 차이점이 있는지 궁금해졌다.
구글링 해서 검색해 보니 메모리 할당과 관련이 있어 보였다. varchar 타입은 지정한 길이만큼 메모리를 할당하여 캐싱해서 사용할 수 있지만, text는 길이를 지정하지 않으니 메모리를 할당할 수 없어서 사용할 때마다 메모리를 할당해줘야 하는 차이점이 있었다.
간단하게 varchar 타입과 text 타입의 사용 기준을 살펴보면 아래와 같다.
※ varchar 타입
- 최대 길이가 상대적으로 크지 않은 경우
- 테이블 데이터를 읽을 때 항상 해당 컬럼이 필요한 경우
- DBMS 서버의 메모리가 상대적으로 충분한 경우
※ text 타입
- 최대 길이가 상대적으로 큰 경우
- 테이블에 길이가 긴 문자열 타입 컬럼이 많이 필요한 경우
- 테이블 데이터를 읽을 때 해당 컬럼이 자주 필요치 않은 경우
varchar 타입과 text 타입의 차이점을 확인해 보니 내가 설계한 테이블에서 속성의 타입을 정할 때 조금 더 명확한 기준이 생긴 것 같았다.
아무래도 게시글 내용 같은 경우에는 상당히 많은 글이 포함되어 있기 때문에 text 타입이 필요할 것이다. 반대로 회원의 이름, 아이디, 게시글의 제목 같은 경우에는 많은 양의 글자수가 필요하지 않기 때문에 varchar로 지정하는 것이 좋을 것 같다.
추가적으로 생각해 보면 회원의 이름이나 게시글 제목 같은 경우에는 상당히 많이 호출되어야 하기 때문에 varchar 타입이 적절하고, 반대로 게시글 같은 경우에는 10개가 있다고 하더라도 10개를 다 확인하는 것이 아닌 이미 본 게시글에 대해서는 확인하지 않기 때문에 자주 필요한 컬럼은 아니라고 판단하였다.
varchar와 text 타입의 차이를 알아보면서 내가 여태 알지 못했던 지식이 상당히 많았었다.
위의 내용도 정말 간략하게만 정리한 거라서 이 부분에 대해서는 더 공부하여 따로 블로그를 작성해 다시 여기에 링크를 걸어둘 생각이다.
참고 자료
'프로젝트' 카테고리의 다른 글
| [NEST] - DOM을 잘 몰라서 발생한 에러 (1) | 2024.10.16 |
|---|---|
| [NEST] - NEST 프로젝트 (0) | 2024.10.16 |
| [RC] - 프로젝트 설계 (3) | 2024.10.14 |
| [프로젝트] - 면접 회고와 추후 계획 (1) | 2024.10.03 |
| [SSM_프로젝트] Spring Netflix Eureka 적용하기 (0) | 2024.06.13 |
DB 설계하기
본격적인 개발을 시작하기에 앞서 DB를 먼저 설계해보려고 한다. DB는 RDBMS 계열의 MySQL을 선택했다.
ERD 그리기
이전 포스팅에서 언급했던 것처럼 회원, 게시판, 댓글 기능에 대해서 테이블을 생성하려고 한다.
먼저 ERD를 그려보면 위의 그림과 같이 표현할 수 있다.
회원은 여러 게시판에 댓글을 작성할 수 있고, 게시판도 여러 회원을 통해서 댓글이 달릴 수 있다. 따라서 다 대 다 관계가 형성되면서 comment(댓글) 테이블로 분리하게 되었다.
ERD를 그려봤으니 이제 테이블 형태로 살펴보자.
테이블로 표현하면 위의 그림과 같이 만들 수 있다. 각 테이블과 연관관계를 아래와 같이 정리해 보았다.
- 한 명의 회원은 여러 개의 게시글을 만들 수 있지만, 하나의 게시글은 오직 한 명에 의해서만 생성될 수 있다.
- 한 명의 회원은 여러 개의 게시글에 댓글을 남길 수 있다. 또한, 하나의 게시글에는 여러 명의 회원들이 댓글을 남길 수 있다.
정규화 진행하기
ERD까지 다 그린 뒤 정규화를 진행해 보았다.
먼저 회원 테이블에 대해서 스키마를 작성해 보면 위의 그림과 같이 만들 수 있다.
[DB] - 정규화
함수 종속(Functional Dependency)정규화를 알아보기 전에 먼저 함수 종속을 알아야 한다. 함수 종속(FD)이란 한 테이블에 있는 두 개의 속성 집합 사이의 제약을 의미한다.만약 특정 X 값에 따라서 Y 값
hotechstory.tistory.com
이전에 정규화를 정리해 보면서 공부했던 것을 프로젝트에 적용해 볼 예정이다. 따라서 먼저 키와 함수 종속(FD)을 파악해 보자.
현재 member 테이블에서 키를 확인해 보면 기본키로 member_idx가 있고, 후보키로는 {member_id}, {member_id, apt_idx} 이 정도 있을 것 같다.
prime-attribute는 member_idx, member_id, member_name, apt_idx가 있고,
non-prime-attribute로는 member_pw, member_age, apt_name, apt_dong, apt_ho, created_at, updated_at이 있다.
알아본 키를 통해서 함수 종속을 찾아보면 아래와 같이 나올 수 있다.
{member_idx} -> {member_id, member_pw, member_name, member_age, created_at, updated_at}
{member_id} -> {member_idx, member_pw, member_name, member_age, created_at, updated_at}
{member_id, apt_idx} -> {member_idx, member_pw, member_name, member_age, apt_name, apt_dong, apt_ho created_at, updated_at}
정규화를 진행해 보면 먼저 1NF에 걸리는 부분은 없으니 바로 2NF로 넘어간다.
현재 non-prime-attribute는 {member_id, apt_idx}에 대해서 부분 함수 종속인 것을 알 수 있다. 왜냐하면 apt_idx만으로도 non-prime-attribute를 결정할 수 있기 때문에 이 부분을 제거하여 완전 함수 종속이 되게 만들어야 한다.
2NF를 진행하게 되면 위의 그림과 같이 테이블이 분리가 된다. 그다음으로 3NF를 진행해야 하지만 3NF의 규칙이 되는 이행적 함수 종속이 없기 때문에 정규화는 종료된다.
최종적으로 정규화된 스키마를 다시 ERD로 그려보았다.
새롭게 apartment라는 테이블이 생성되면서 기존의 member 테이블과 관계를 맺어주었고, member 테이블에서 apt_idx를 외래키로 지정해 주었다.
varchar와 text 타입의 차이
테이블을 설계하면서 한 가지 의문점이 있었는데 바로 varchar와 text 타입의 차이점이었다.
varchar는 길이를 지정해서 사용할 수 있고, text는 따로 지정 없이 사용할 수 있다 정도로만 알고 있었는데 정확히 어떤 차이점이 있는지 궁금해졌다.
구글링 해서 검색해 보니 메모리 할당과 관련이 있어 보였다. varchar 타입은 지정한 길이만큼 메모리를 할당하여 캐싱해서 사용할 수 있지만, text는 길이를 지정하지 않으니 메모리를 할당할 수 없어서 사용할 때마다 메모리를 할당해줘야 하는 차이점이 있었다.
간단하게 varchar 타입과 text 타입의 사용 기준을 살펴보면 아래와 같다.
※ varchar 타입
- 최대 길이가 상대적으로 크지 않은 경우
- 테이블 데이터를 읽을 때 항상 해당 컬럼이 필요한 경우
- DBMS 서버의 메모리가 상대적으로 충분한 경우
※ text 타입
- 최대 길이가 상대적으로 큰 경우
- 테이블에 길이가 긴 문자열 타입 컬럼이 많이 필요한 경우
- 테이블 데이터를 읽을 때 해당 컬럼이 자주 필요치 않은 경우
varchar 타입과 text 타입의 차이점을 확인해 보니 내가 설계한 테이블에서 속성의 타입을 정할 때 조금 더 명확한 기준이 생긴 것 같았다.
아무래도 게시글 내용 같은 경우에는 상당히 많은 글이 포함되어 있기 때문에 text 타입이 필요할 것이다. 반대로 회원의 이름, 아이디, 게시글의 제목 같은 경우에는 많은 양의 글자수가 필요하지 않기 때문에 varchar로 지정하는 것이 좋을 것 같다.
추가적으로 생각해 보면 회원의 이름이나 게시글 제목 같은 경우에는 상당히 많이 호출되어야 하기 때문에 varchar 타입이 적절하고, 반대로 게시글 같은 경우에는 10개가 있다고 하더라도 10개를 다 확인하는 것이 아닌 이미 본 게시글에 대해서는 확인하지 않기 때문에 자주 필요한 컬럼은 아니라고 판단하였다.
varchar와 text 타입의 차이를 알아보면서 내가 여태 알지 못했던 지식이 상당히 많았었다.
위의 내용도 정말 간략하게만 정리한 거라서 이 부분에 대해서는 더 공부하여 따로 블로그를 작성해 다시 여기에 링크를 걸어둘 생각이다.
참고 자료
'프로젝트' 카테고리의 다른 글
| [NEST] - DOM을 잘 몰라서 발생한 에러 (1) | 2024.10.16 |
|---|---|
| [NEST] - NEST 프로젝트 (0) | 2024.10.16 |
| [RC] - 프로젝트 설계 (3) | 2024.10.14 |
| [프로젝트] - 면접 회고와 추후 계획 (1) | 2024.10.03 |
| [SSM_프로젝트] Spring Netflix Eureka 적용하기 (0) | 2024.06.13 |