
AWS S3

AWS S3 공식 사이트에 가서 설명을 보면 AWS S3는 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스라고 설명해 준다.
여기서 알아볼 것은 S3가 어떤 기능 및 성능을 제공하는지 보다 객체 스토리지 서비스가 뭔지를 파악해야 한다.
객체 스토리지 서비스를 쉽게 생각해 보면 어떠한 데이터(객체)를 어떤 저장 공간(스토리지)에 저장하여 사용자가 사용할 수 있게 해주는 서비스라고 생각하면 될 것 같다.
AWS S3 공식 사이트에서 제공하는 S3의 작동 방식을 살펴보며 개념을 확인해 보자.
AWS S3의 작동 방식
AWS S3의 작동 방식은 먼저 버킷을 생성하고 버킷의 이름과 리전을 지정해 준 다음 내가 업로드하고 싶은 데이터 업로드 하면 S3가 해당 데이터를 객체로 만들어서 버킷에 업로드를 해준다.
그럼 여기서 살펴볼 2가지 포인트는 ⓛ데이터가 업로드되는 버킷이 무엇인지, ②S3에서 데이터를 어떻게 객체로 저장해 주는지이다.
1. 버킷
S3 공식 사이트에서 살펴보면 버킷은 저장된 객체에 대한 컨테이너라고 한다.
쉽게 말해서 우리가 어떤 데이터를 업로드할 저장소 즉, 처음에 언급했던 S3 설명 중 객체 스토리지 서비스에서 스토리지를 의미한다.
버킷에 저장할 수 있는 개체의 수에는 제한이 없으며 계정마다 버킷을 최대 100개까지 생성할 수 있다고 한다.
2. S3에서 데이터를 객체로 저장
S3 버킷에 각종 데이터를 업로드하기 위해서는 AWS에서 제공하는 SDK를 사용해야 한다.
진행하고 있는 Spring 프로젝트에서 Java로 작성한 코드를 살펴보자.
public String saveFile(MultipartFile productFile) {
String originalName = productFile.getOriginalFilename();
String folderPath = makeFolder();
String uuid = UUID.randomUUID().toString();
String saveFileName = folderPath + File.separator + uuid + "_" + originalName;
try {
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentLength(productFile.getSize());
metadata.setContentType(productFile.getContentType());
s3.putObject(bucket, saveFileName.replace(File.separator, "/"), productFile.getInputStream(), metadata);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
// 로컬 파일 시스템에서 파일 삭제
File localFile = new File(saveFileName);
if (localFile.exists()) {
localFile.delete();
}
return s3.getUrl(bucket, saveFileName.replace(File.separator, "/")).toString();
}
}이미지를 S3 버킷에 업로드하는 saveFile 메서드를 살펴보면 s3.putObject() 메서드를 사용하여 이미지를 업로드하는 것을 알 수 있다.
이미지가 업로드된 후 s3.getUrl() 메서드를 통해서 방금 업로드한 파일의 경로를 받아 DB에 저장하면 프론트에서 접근이 가능하게 된다. (SDK를 사용하는 방법은 추후에 정리할 예정)
S3에 데이터를 업로드하게 되면 https://[BucketName].[Region].[amazonaws.com]/object/key.name 이런 식으로 주소가 지정된다.
S3는 단순한 구조를 가지고 있어 하위 버킷 또는 하위 폴더의 계층 구조라는 것이 없다. 다만 Amazon S3 콘솔은 폴더 개념을 지원하기 때문에 객체 키 이름의 접두사 및 구분 기호(/)를 보고 논리적인 계층 구조를 추론할 수 있다.
예를 들어 리전을 서울로 지정하고 버킷 이름을 TEST라고 가정해 보자 그리고 test/test.txt 파일을 업로드한다고 했을 경우 아래와 같이 URL 주소가 만들어진다.
https://TEST.s3.ap-northeast-2.amaznoaws.com/test/test.txt
위와 같이 저장되고 S3에서 확인해 보면 test라는 폴더에 test.txt 파일이 있는 것을 확인할 수 있다.
여기서 고려해야 될 점은 접두사 및 구분기호를 사용하여 추론을 하기 때문에 test/ 없이 test.txt만 작성하면 폴더 없이 파일만 올라가게 된다.
AWS S3를 사용하는 이유
1. 저장 용량이 무한대이고 파일 저장에 최적화되어 있다.
2. S3는 수백만 개의 웹 서버로 구성되어 있어 Auto Scaling이나 Load Balancing 같은 작업이 필요하지 않다.
3. AWS EBS, EFS 같은 스토리지 서비스보다 비용이 저렴하다.
4. 정적 리소스를 버킷에 업로드하여 S3만으로 정적 웹 서비스가 가능하다.
S3 버킷 생성하기
이제부터 AWS S3 버킷을 생성하는 방법을 알아보자.
참고로 프리티어 기준 standard 타입으로 매달 5GB까지 GET 요청은 20,000건, PUT 요청은 2,000건 무료다.
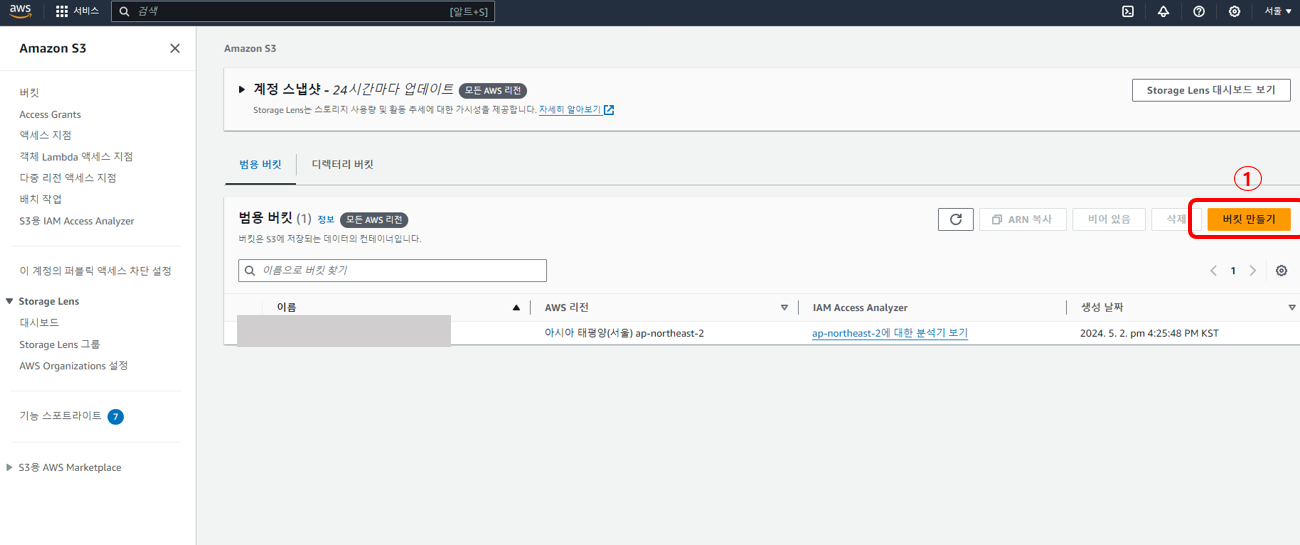
1. S3 페이지로 이동하여 버킷 만들기를 클릭한다.
※ 생성하기 전에 현재 내가 설정한 리전을 꼭 확인해야 한다. 잘못하면 엉뚱한 리전에서 S3가 생성될 수 있다.
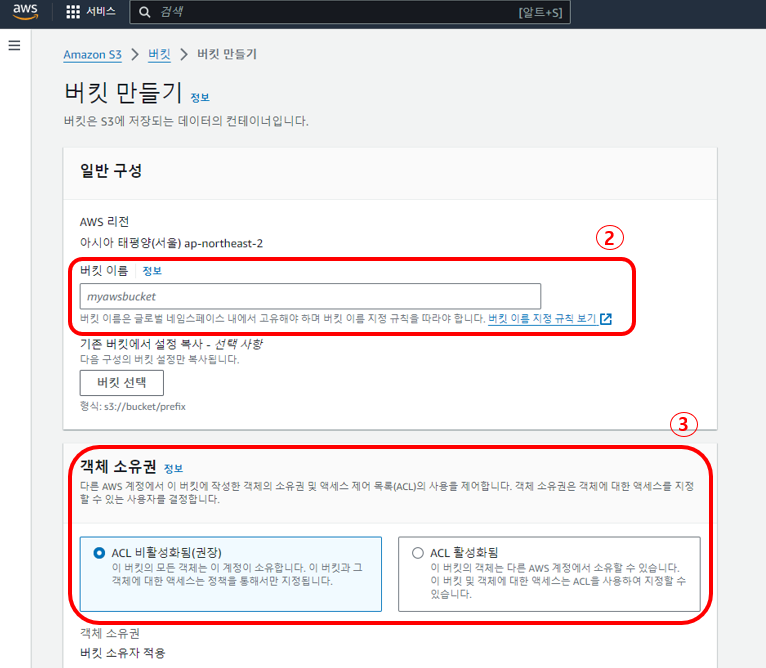
2. 먼저 버킷 이름을 지정해 주는데 버킷 이름은 전 세계에서 고유해야 하고 규칙이 따로 존재하기 때문에 잘 확인해서 지정해 준다.
3. 그다음 ACL을 설정하는데 비활성화로 해준다.
ACL은 다른 AWS 계정에서도 해당 버킷에 대한 소유권을 갖거나 접속 제어를 가능하게 할 것인지 유무를 물어보는 것으로 비활성화로 설정하면 내가 접속한 계정만 버킷을 소유하게 된다.
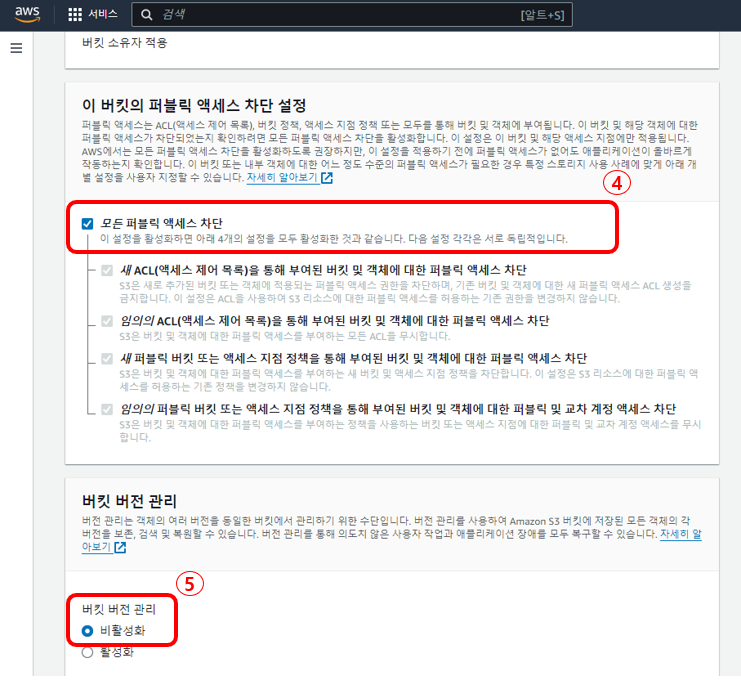
4. 내가 만들 버킷의 퍼블릭 액세스를 차단할 것인지 설정해 준다. 만약 모두 차단하게 되면 외부에서 버킷 내에 있는 파일을 읽지 못한다는 뜻으로 필요에 따라서 차단을 설정해 주면 된다.
5. 버킷 버전 관리 설정은 내가 업로드할 파일을 버전별로 관리할 것인지를 의미한다. 만약 버전별로 관리한다면 실수로 파일을 삭제해도 복원이 가능하지만 추가적인 비용이 들게 된다.
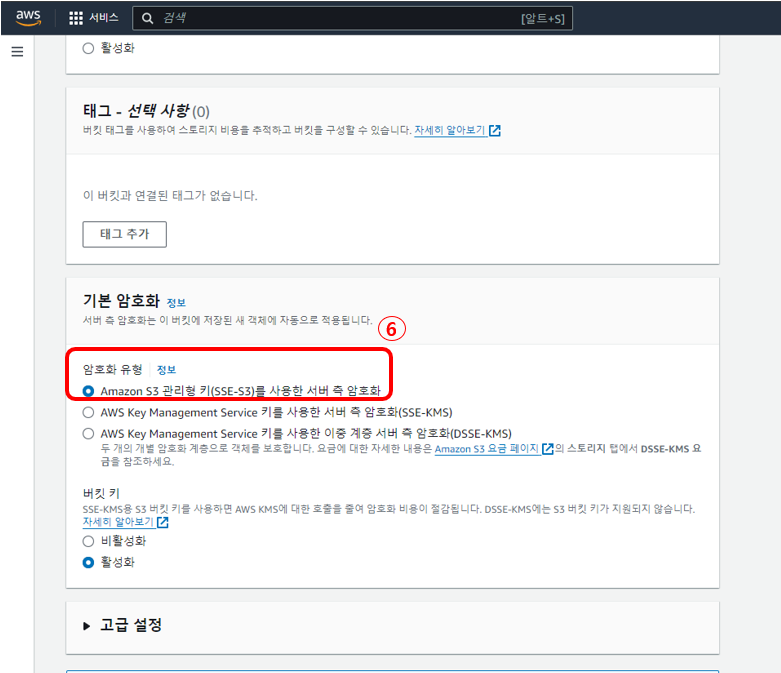
6. 기본 암호화는 버킷에 저장되는 모든 새 객체를 암호화해서 저장하고 해당 객체를 다운할 경우 암호를 복호화해서 제공해 주는 설정으로 Amazon S3 관리형 키로 설정한다.
마지막으로 버킷 키 설정은 암호화 유형에서 관리형 키를 선택했기 때문에 관련 옵션을 비활성화를 해준다.
S3 버킷 정책 생성
외부에서 버킷에 접근 가능하도록 하기 위해서는 버킷 정책을 생성해야 한다.
버킷 정책이란 적절한 권한을 가진 사용자만 객체에 액세스 할 수 있도록 하는 것이다.

7. 버킷 정책 편집으로 이동하여 정책 생성기를 클릭한다. 버킷 정책은 JSON 형태로 작성되는데 생성기를 통해서 몇 가지 설정을 해주면 JSON 형태로 작성해 준다.
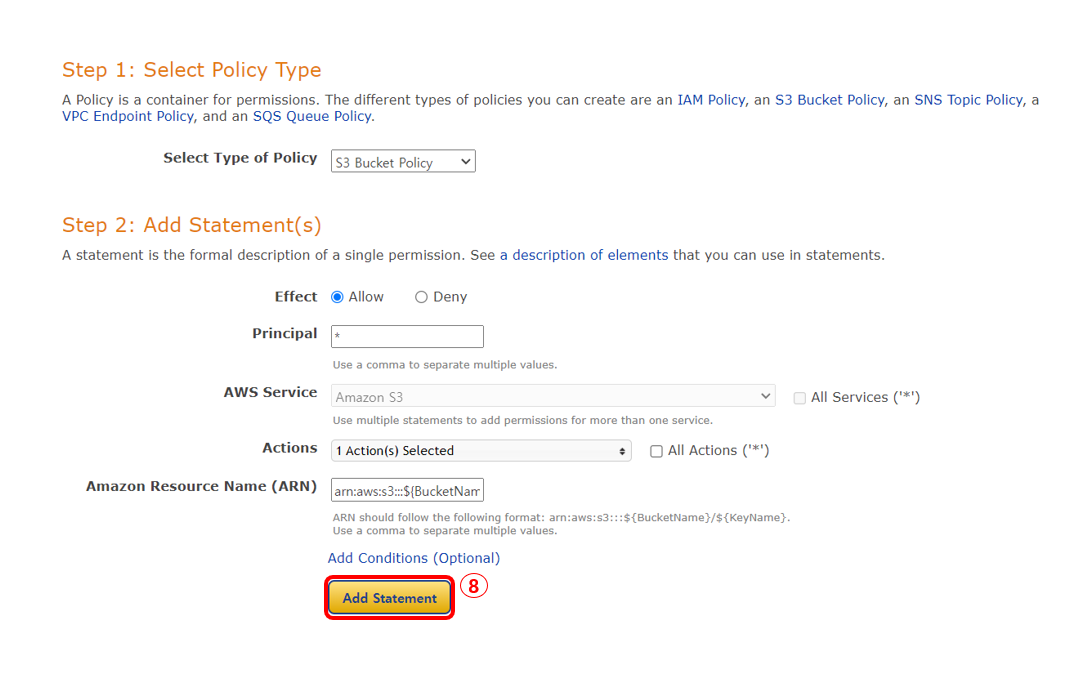
정책 생성기를 하나씩 살펴보면 아래와 같다.
1. Select Type of Policy: 어떤 정책을 생성할 것인지 타입을 지정한다.
2. Effect: 정책을 적용(Allow)할 것인지, 거부(Deny)할 것인지 정한다.
3. Principal: 정책이 적용될 대상을 지정한다. ('*'은 전체를 의미)
4. Actions: 어떤 액션을 수행할 것인지 지정한다.(GetObject, PutObject 등)
5. Amazon Resource Name(ARN): 어떤 리소스에 정책을 적용할 것인지 지정한다.
설정을 모두 완료했다면 Add Statement를 클릭한다.
Add Statement를 클릭하게 되면 Generate Policy 버튼이 뜨는데 클릭하면 JSON 형태의 정책을 내가 설정한 옵션대로 생성해 준다.
마지막으로 해당 JSON 형태의 정책을 복사하여 정책 편집으로 이동 후 붙여 넣기를 하고 저장한다.