
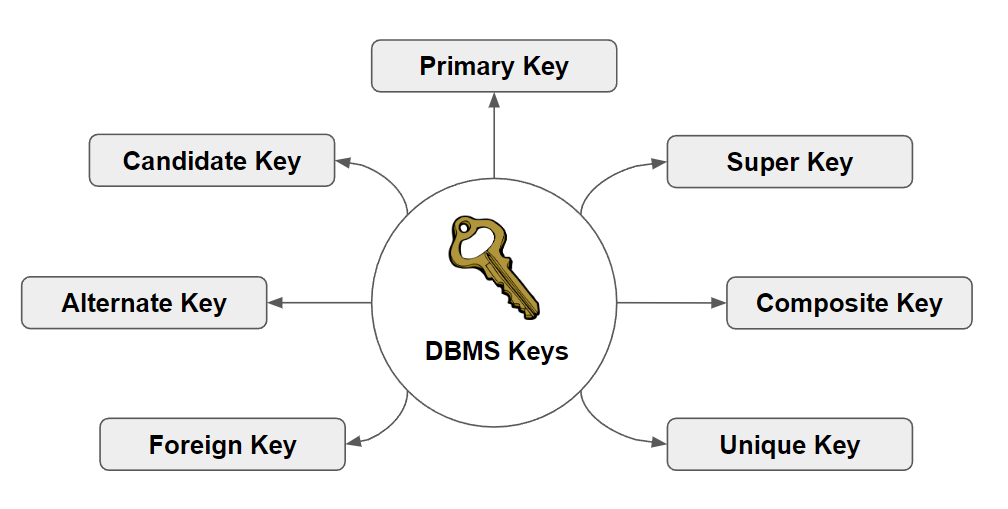
키(Key)
방대한 양의 데이터를 관리한다고 생각해 보자. 각 데이터가 정확히 있어야 할 위치에 있는지, 데이터 간의 관계가 유지되는지, 중복이 없는지 등과 같은 것을 어떻게 보장할 수 있을까?
내가 생각했을때 데이터가 어디에 위치해 있는지, 어떤 관계를 맺고 있는지, 중복은 없는지 등과 같은 것을 여러 가지로 어떤 표시를 해두면 쉽게 보장할 수 있을 것 같다고 생각한다.
이러한 특정 표시는 데이터를 관리할 수 있는 시스템인 DBMS(Database Management System)에서 키(Key)라고 부른다.
DBMS에서 키는 데이터의 효율적인 구성 및 검색을 가능하게 하는 필수 구성 요소이다. 앞서 설명했던 것처럼 키를 통해서 데이터의 위치나 관계 등과 같은 것들을 보장할 수 있기 때문이다.
또한, 키를 사용하게 되면 행을 쉽게 선택하고 다른 행과 분리하여 계산에 사용할 수 있다.
- 간단한 DBMS 용어 설명

DBMS에 관한 자료들을 찾아보면 각자 사용하는 용어가 조금씩 달라서 헷갈릴 때가 많았다.
용어는 알아두면 다른 공식 문서나 공부할 때 유용할 것 같아서 간단하게라도 정리해 보자.
- 행(Row, Record)
행(Row)은 레코드라고도 불리며 논리적으로 연관된 필드의 집합을 의미한다. 이렇게 말하면 조금 어렵게 느껴질 수 있는데, 간단하게 설명하면 여러 속성의 값들이 모여 하나의 행을 이루게 된다는 뜻이다.
위의 테이블을 예시로 들면 각 속성들인 ID, 이름, 나이, 전화번호를 모아서 하나의 레코드로 구성하게 된다.
- 열(Field, Column)
열(Column) 혹은 필드라고 불리는 부분은 가장 작은 단위의 데이터를 의미하며 엔티티의 속성을 표현한다. 위의 테이블을 예시로 들면 각 열은 ID, 이름, 나이, 전화번호를 나타낸다.
DBMS에서 키의 중요성
DBMS에서 키가 중요한 이유는 데이터의 무결성을 구성, 구조화 및 유지하는 데 있어 기본적인 역할을 할 수 있기 때문이다.
- 데이터의 무결성 4가지
앞서 키가 중요한 이유 중 무결성을 언급했는데, 무결성에도 4가지 종류가 있다.
- 개체 무결성: 다양한 방식으로 사용 및 연결할 수 있는 테이블 내에 데이터를 저장하는 관계형 데이터베이스의 기능이다. 데이터를 식별하기 위해 생성된 고유 키와 값에 의존하여 동일한 데이터가 여러 번 나열되지 않고 필드가 올바르게 채워지도록 보장한다.
- 참조 무결성: 데이터가 균일한 방식으로 저장되고 사용되는 것을 보장하는 일련의 프로세스이다. 데이터베이스 구조에는 외래 키가 사용되는 방법을 정의하는 규칙이 내장되어 있어 적절한 데이터 삭제, 변경 및 수정만 수행할 수 있다. 이를 통해 데이터 중복을 방지하고 데이터베이스 전체에서 데이터의 일관성을 유지할 수 있다.
- 도메인 무결성: 도메인 내의 데이터 조각의 정확성을 보장하는 일련의 프로세스이다. 도메인은 테이블의 열이 포함할 수 있는 값 집합과 입력할 수 있는 데이터의 양, 형식 및 유형을 제한하는 제약 조건 및 측정값으로 분류된다.
- 사용자 정의 무결성: 사용자가 특정 요구 사항에 맞게 데이터 주변의 규칙과 제약 조건을 만드는 것을 의미한다. 이는 일반적으로 다른 무결성 프로세스가 조직의 데이터를 보호하지 못할 때 사용되어 조직의 데이터 무결성 측정을 통합하는 규칙을 만들 수 있다.
1. 고유성 및 식별
키 중에서 특히 기본 키는 테이블의 각 레코드의 고유성을 보장한다. 이 고유성은 한 레코드를 다른 레코드와 정확하게 식별하고 구별하고 중복을 방지하며 데이터 정확성을 보장하는 데 필수적이다.
2. 테이블 간의 관계
외래 키는 한 테이블의 기본 키를 다른 테이블의 외래 키에 연결하여 테이블 간의 관계를 설정한다.
이 관계는 서로 다른 데이터 집합 간의 연결 및 종속성을 생성하여 데이터 일관성과 응집력을 증진한다.
3. 데이터 무결성
키는 데이터베이스의 무결성을 유지하는 데 중요한 역할을 한다.
규칙과 제약 조건을 시행하여 일관되지 않거나 잘못된 데이터 입력을 방지한다.
이를 통해 데이터베이스에 저장된 데이터가 나타내는 실제 엔티티를 정확하게 반영하도록 한다.
4. 효율적인 데이터 검색
키에 대한 인덱싱은 데이터 검색 작업의 효율성을 향상한다.
특정 레코드를 검색하고 액세스한느 것이 더 빠르고 간소화되어 데이터베이스 시스템의 전반적인 성능에 기여한다.
5. 최적화된 쿼리 실행
키는 쿼리 실행 계획의 최적화를 용이하게 한다. 고유 식별자와 관계를 제공함으로써 데이터베이스 엔진은 데이터를 효율적으로 검색하고 조인하여 더 빠르고 효율적인 쿼리 처리를 이룰 수 있다.
키의 종류
이제 본격적으로 키의 종류에 대해서 알아보자. (개념을 정리한 키는 총 7가지지만 이것 외에도 더 있다.)
- 기본 키(Primary Key)
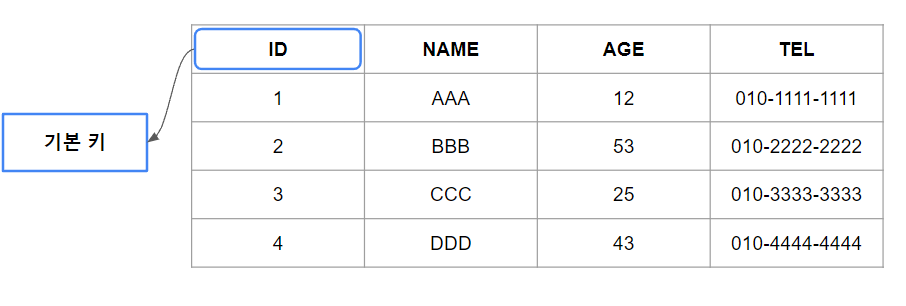
기본 키는 고유 키로, 테이블에서 단 하나의 행만 식별한다.
기본 키는 데이터베이스에서 테이블의 고유한 레코드를 식별하도록 지정된 후보 키 중에서 선정이 된다.
기본 키는 테이블 내에서 단 하나만 가질 수 있기 때문에 테이블의 각 레코드에 대한 고유 식별자 역할을 한다. 이를 통해서 데이터 무결성을 보장하고 테이블 간의 관계를 용이하게 한다.
기본 키를 통해서 레코드를 식별해야 되기 때문에 값이 변하면 안 되고(불변성), 중복되지 않는 값(고유성)을 사용해야 하며 NULL 값을 사용할 수 없다.
중복 항목을 방지하고 데이터베이스 내 관계에 대한 신뢰할 수 있는 참조점을 설정하기 때문에 데이터 정확성을 유지하는 역할이 중요하다.
- 후보 키(Candidate Key)
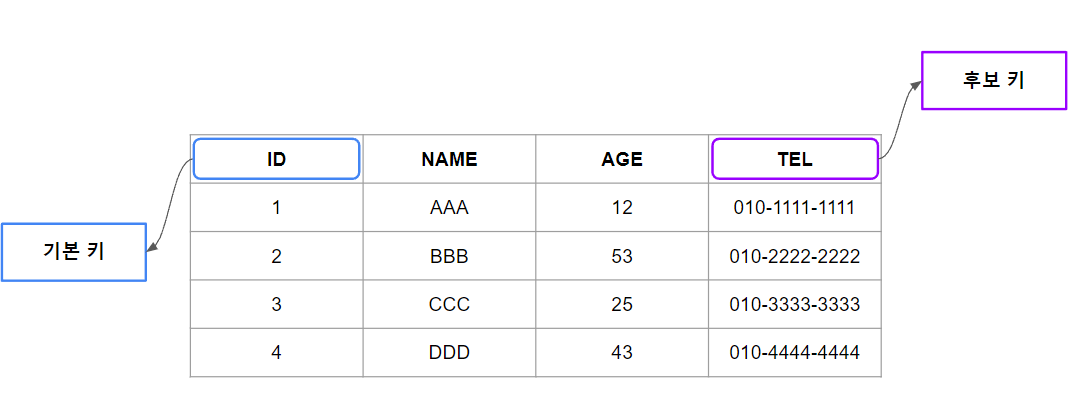
후보 키는 테이블의 행을 고유하게 식별할 수 있는 테이블 열 또는 열의 집합으로 하나 이상이 존재할 수 있다.
이러한 여러 후보 키들 중에서 기본 키가 선정된 뒤 테이블의 행을 고유하게 식별할 수 있는 다른 열은 후보 키로 남게 된다.
중간에 기본 키가 바뀔 수도 있고, 그럴 경우에는 후보 키들 중에서 선택되므로 후보 키를 잠재적인 기본 키라고도한다.
후보 키가 되려면 속성 집합이 각 레코드에 대해 고유해야 하며 이러한 속성의 하위 집합은 동일한 속성을 가져서는 안 된다.
후보 키는 슈퍼 키에서 선택된다.
- 외래 키(Foreign Key)

외래 키는 한 관계의 키로 다른 테이블의 기본 키를 참조하여 관계를 설정해 준다.
관계형 데이터베이스에서 외래 키가 중요한데 개념 그대로 관계를 형성할 수 있기 때문이다.
외래 키의 특징을 살펴보면 3가지가 있다.
1. 참조 테이블의 기본 키 열에 의해 타입이나, 범위 등 제한된다.
2. 외래 키 제약 조건으로 인하여 데이터를 삭제하는데 제약이 생긴다.
3. 참조 무결성을 강제하여 테이블 간의 관계가 유지된다.
이러한 외래키를 사용하면 테이블에서 다른 테이블의 기본 키를 참조하여 종속성을 설정하고 서로 다른 데이터 집합 간에 의미 있는 연결을 설정할 수 있다.
- 슈퍼 키(Super Key)
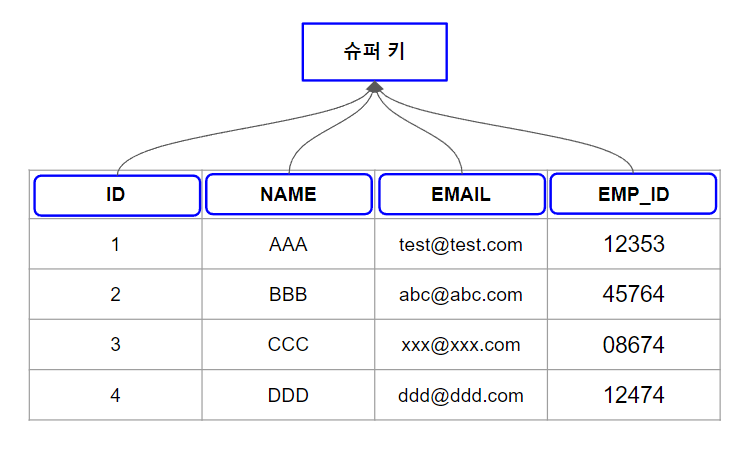
슈퍼 키는 테이블 내의 레코드를 고유하게 식별하는 하나 이상의 속성 집합이다.
후보 키, 기본 키, 복합 키를 포함한 다양한 유형의 키를 포함하는 더 광범위한 개념을 나타낸다.
기본적으로 레코드를 고유하게 식별하는 속성의 모든 조합은 슈퍼 키로 간주될 수 있다.
- 대체 키(Alternate Key)
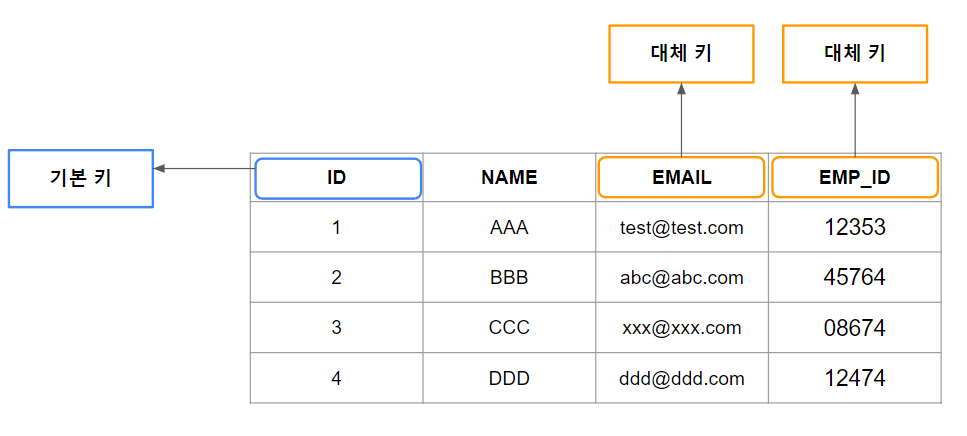
앞서 후보 키를 설명할 때 기본 키로 선정된 후 다른 후보 키들이 남게 된다고 했는데 이러한 기본 키로 선택되지 않은 후보 키를 대체 키라고 한다.
대체 키는 이름 그대로 대체 옵션을 말하는데 기본 키를 사용할 수 없거나 실용적이지 않은 경우 대체 키가 기본 키 기능을 할 수 있다.
대체 키를 통해서 조금 더 유연한 데이터 검색을 할 수 있다.
- 복합 키(Composite Key)
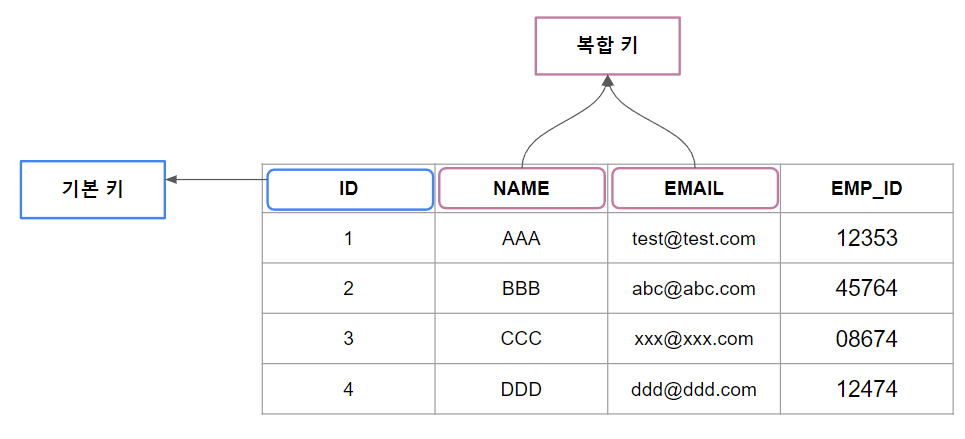
복합 키는 테이블의 두 개 이상의 열을 조합한 것으로 함께 해당 테이블 내의 각 레코드를 고유하게 식별한다.
단일 열 기본 키와 달리 복합 키는 여러 필드를 사용하여 고유성을 보장한다.
단일 속성만으로는 레코드를 고유하게 식별할 수 없을 경우 두 개 이상의 속성을 결합하여 새로운 고유 식별자를 만드는데 이것이 복합 키이다.
복합 키의 결합된 값은 고유해야 하며 각 행에 대한 집합 식별자 역할을 한다.
복합 키는 레코드를 고유하게 식별하는 강력한 수단을 제공하지만 쿼리를 더 복잡하게 만들 수 있다.
- 고유 키 - 유일 키(Unique Key)
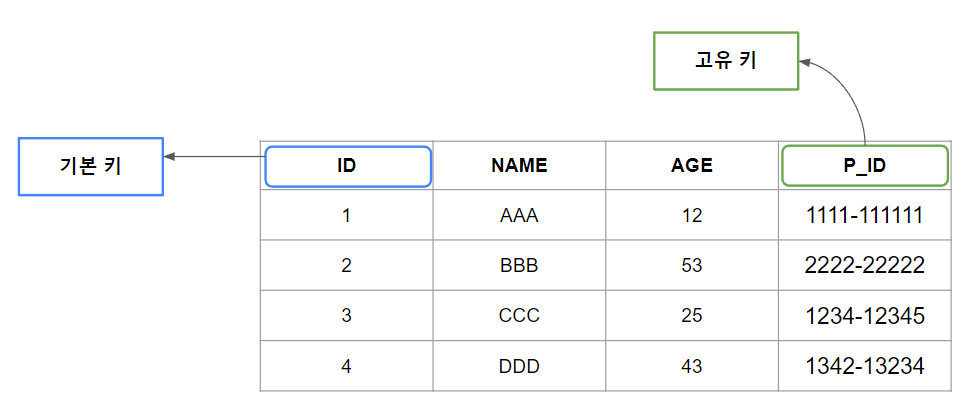
고유 키는 테이블 내의 지정된 열 또는 열 집합에 있는 값의 고유성을 보장하는 제약 조건(Unique)이다. 이를 통해서 중복 항목이 존재하지 않도록 보장한다.
그림과 같이 주민번호인 P_ID에 Unique 제약조건을 걸어서 고유 키로 만들 수 있다.
기본 키와 달리 고유 키는 반드시 레코드를 식별하는 주요 수단으로 사용되지는 않지만 중복을 방지하여 데이터 무결성을 적용하는데 필수적이다.
참고 자료
Types of Keys in DBMS: Your Key to Database Success
There are Seven types of keys in DBMS. These keys included the primary key, foreign key, candidate key, super key, alternate key, composite key, & unique key.
www.theknowledgeacademy.com
7 Keys in Database…
Understanding the World of DBMS: All About Keys
medium.com
What is Data Integrity? | IBM
Data integrity means that data remains accurate, complete and consistent throughout its lifecycle, and verifies data is not altered without authorization.
www.ibm.com
Super key in DBMS
beginnersbook.com
'CS > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 - 고립화 수준과 이상 현상 (2) | 2024.08.05 |
|---|---|
| 데이터베이스 - 동시성 제어 (0) | 2024.08.05 |
| 데이터베이스 - 트랜잭션 (0) | 2024.08.04 |
| 데이터베이스 - ERD (0) | 2024.08.01 |
| [DB] - 대규모 데이터 처리 (0) | 2024.06.12 |