
JVM(Java Virtual Machine)

우리가 사용하는 컴퓨터는 0과 1로 이루어진 숫자만 이해할 수 있다. 하지만 개발할 때 보면 문자, 0과 1이 아닌 숫자들도 많이 사용하게 되는데 이러한 내용들은 컴퓨터가 바로 이해할 수 없다.
따라서 작성한 코드를 컴퓨터가 이해할 수 있는 0과 1의 숫자로 변환해주는 작업이 필요하게 되는데 이러한 과정을 컴파일이나 인터프리트라고 한다.

컴파일과 인터프리트의 차이를 잠깐 살펴보면 먼저 컴파일은 프로그램을 실행하기 전에 해당 코드들을 컴퓨터가 읽을 수 있는 0과 1의 숫자로 변환해주는 작업이다.
컴파일 과정을 거치면 미리 변환해주는 과정을 거쳐야 되지만 이를 통해서 사전에 문제가 될 수 있는 부분들이 걸러질 수 있고, 변환된 코드를 컴퓨터가 한 번에 읽을 수 있기 때문에 실행 속도가 빠르다.
반대로 인터프리트는 프로그램을 실행할 때마다 인터프리터라는 프로그램이 코드들을 컴퓨터가 읽을 수 있는 0과 1의 숫자로 변환해주게 된다.
사전에 코드를 변환하는 과정이 없기 때문에 컴파일 과정보다 개발을 조금 수월하게 할 수 있지만 반대로 사전에 문제가 될 수 있는 부분을 걸러내기 어렵고, 매번 인터프리터 프로그램이 변환해줘야 하기 때문에 실행 속도가 느리다는 단점이 있다.
자바 언어는 위의 설명 중에서 컴파일 과정을 통해 프로그램을 실행시키게 된다.

하지만 이런 컴파일 과정은 운영체제의 종류에 따라 따로 해줘야하기 때문에 많은 번거러움이 생기게 된다.
이러한 번거러움을 해결하기 위해 자바에서는 JVM이라는 것을 도입하게 된다.
JVM은 자바 가상 머신을 의미하며 운영체제와 상관없이 어떤 곳에서도 자바 클래스 파일이 실행되도록 하는 바이트코드 인터프리터 및 런타임으로 구성된다.

자바로 된 프로그램은 먼저 자바 바이트코드로 컴파일된 후 각 PC에 설치된 JVM을 통해서 운영체제에 맞도록 변환된다.
이를 통해서 개발자는 어떤 플랫폼인지 신경쓰지 않고 개발할 수 있게 되면서 자바 언어의 슬로건인 "Write Once, run anywhere" 가 실현되는 것이다.
JVM에 디테일한 설명에 들어가기 앞서 간단한 과정을 살펴보면 아래의 그림과 같다.

먼저 .java 파일을 컴파일하면 동일한 클래스 이름을 가진 .class 파일(자바 바이트코드)이 java 컴파일러에 의해 생성된다. 그 후 .class 파일을 실행했을 때 JVM을 통해서 여러 처리 과정을 거쳐 프로그램이 실행된다.
JVM의 구조
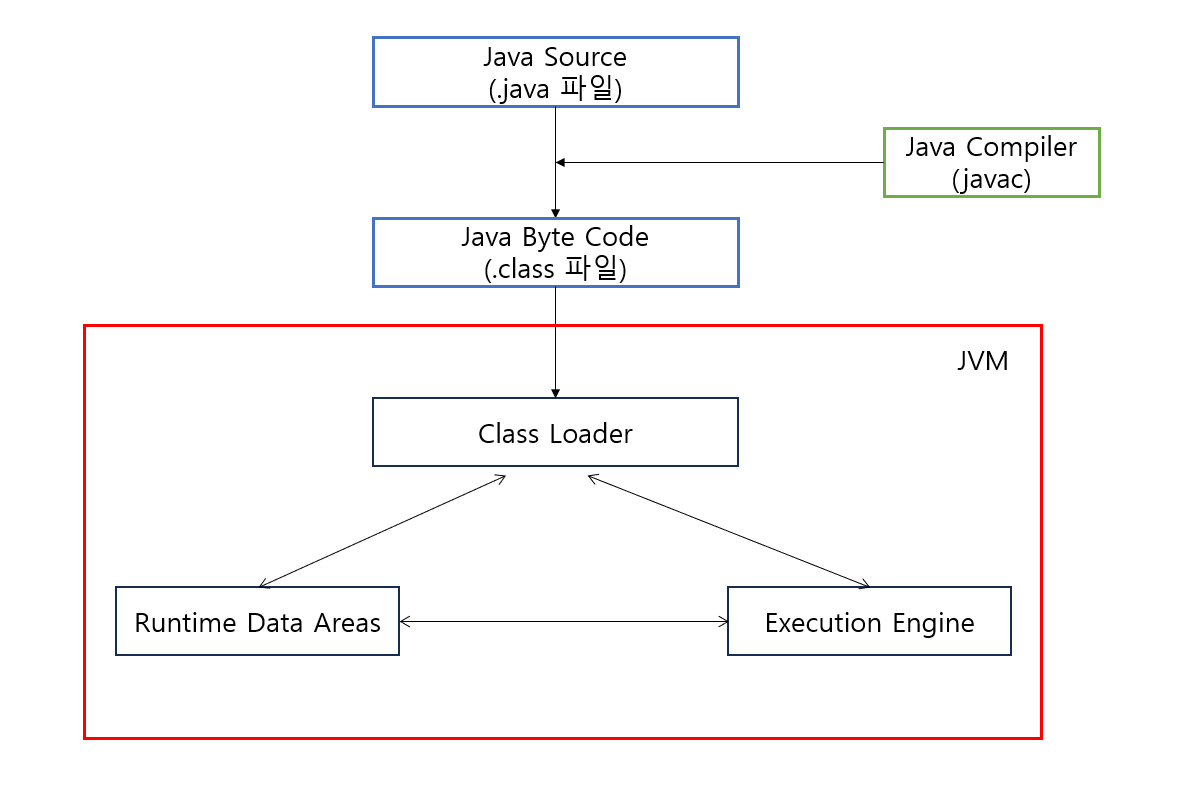
위의 그림은 JVM 구조로 자바로 작성한 코드는 위와 같은 과정을 통해 수행된다.
하나씩 살펴보면 다음과 같은 순서로 동작한다.
1. 자바 프로그램을 실행하면 JVM은 OS로부터 메모리를 할당받는다.
2. 자바 컴파일러(javac)가 자바 소스코드(.java)를 자바 바이트 코드(.class)로 컴파일한다.
3. Class Loader는 동적 로딩을 통해 필요한 클래스들을 로딩 및 링크하여 Runtim Data Areas에 올린다.
4. Runtime Data Areas에 로딩된 바이트 코드는 Execution Engine을 통해 해석된다.
5. Execution Engine에 의해 Garbage Collector의 작동과 Thread 동기화가 이루어진다.
JVM 영역은 Class Loader, Runtime Data Areas, Execution Engine 총 3가지인데 하니씩 상세하게 살펴보자.
클래스 로더(Class Loader)
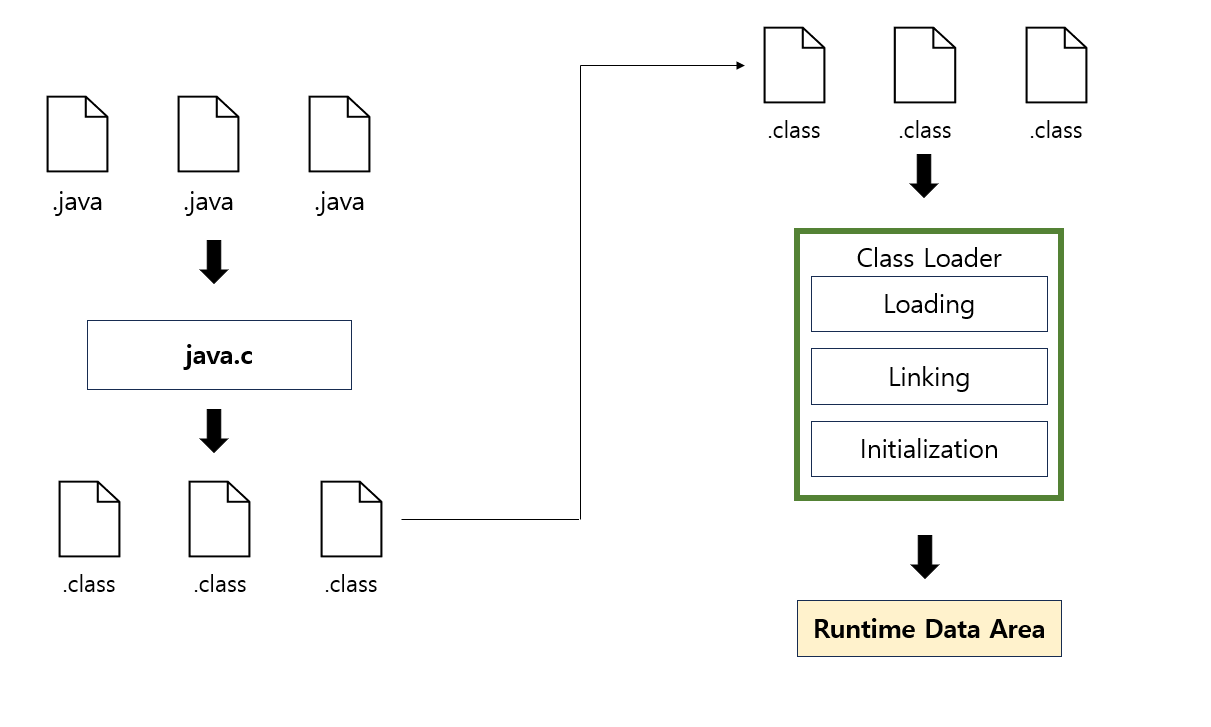
자바는 동적으로 클래스를 읽어오므로 프로그램이 실행 중인 런타임 영역에서야 모든 코드가 JVM과 연결된다. 이렇게 동적으로 클래스를 로딩해 주는 역할을 하는 것이 클래스 로더이다.
자바에서 소스 코드를 작성하면 .java 파일이 생성되고 해당 파일을 컴파일하면 .class 파일이 생성되는데 로드된 바이트 코드들 즉, .class 파일들을 엮어서 JVM의 메모리 영역인 런타임 데이터 영역으로 배치한다.
클래스를 메모리에 올리는 로딩 기능은 한 번에 메모리에 올리지 않고 애플리케이션에서 필요한 경우 동적으로 메모리에 적재하게 된다.
클래스 파일의 로딩 순서는 3단계를 거치게 된다.

1. Loading(로드): 클래스 파일을 가져와서 JVM의 메모리에 로드한다.
2. Linking(링크): 클래스 파일을 사용하기 위해 검증하는 과정이다.
- Verifying(검증): 읽어 들인 클래스가 JVM 명세에 명시된 대로 구성되어 있는지 검사한다.
- Preparing(준비): 클래스가 필요로 하는 메모리를 할당한다.
- Resolving(분석): 클래스의 상수 풀 내 모든 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변경한다.
3. Initialization(초기화): 클래스 변수들을 적절한 값으로 초기화한다. (static 필드들을 설정된 값으로 초기화 작업 등)
런타임 데이터 영역(Runtime Data Areas)
런타임 데이터 영역은 JVM의 메모리 영역으로 자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역이다.

위의 그림에서 Thread로 표시한 3개의 영역은 각각의 스레드마다 하나씩 생성되는 영역이고, 나머지 2개의 영역은 모든 스레드가 공유해서 사용하는 메모리 영역이다.
메모리 영역을 하나씩 살펴보자.
Method(Static) Area
메서드 영역은 JVM이 시작될 때 생성되는 공간으로 바이트 코드(.class)를 처음 메모리 공간에 올릴 때 초기화되는 대상을 저장하기 위한 메모리 공간이다.
JVM이 동작하고 클래스가 로드될 때 적재돼서 프로그램이 종료될 때까지 저장된다.
모든 스레드가 공유하는 영역으로 초기화 코드 정보들이 저장되게 된다.
- Field Info: 멤버 변수의 이름, 데이터 타입, 접근 제어자 정보
- Method Info: 메서드 이름, 반환 타입, 매개 변수, 접근 제어자의 정보
- Type Info: Class인지 Interface인지 여부 저장, Type의 속성, Super Class의 이름
쉽게 말하면 메서드 영역은 정적 필드와 클래스 구조만을 갖고 있다.
Heap Area
힙 영역은 객체가 생성되거나 객체가 저장되는 메모리 영역이다.
우리가 객체를 생성할 때 사용하는 new 키워드로 생성된 객체 혹은 배열이 생성되는 메모리 영역이다.
메서드 영역에 저장된 클래스만이 생성이 되어 적재된다. (당연히 메서드 영역에 없는 클래스는 객체 생성이 안됨)
힙 영역에서 주의할 점은 해당 영역에서 생성된 객체와 배열은 참조 타입으로 JVM 스택 영역의 변수나 다른 객체의 필드에서 참조된다는 것이다.
힙의 참조 주소는 스택이 갖고 있고 해당 객체를 통해서만 힙 영역에 있는 인스턴스를 핸들링할 수 있다.
만약 참조하는 변수나 필드가 없다면 의미 없는 객체가 되므로 해당 객체는 JVM이 GC를 실행시켜 힙 영역에서 자동으로 제거시킨다.
Stack Area
각 스레드에는 스레드와 동시에 생성된 전용 JVM 스택이 있다.
주로 지역 변수, 매개 변수, 리턴 값, 연산에 사용되는 임시 값 등이 생성되는 영역이다.
int, long, boolean 등 기본 자료형을 생성할 때 저장하는 공간
자바로 프로그래밍을 하다 보면 볼 수 있는 StackOverFlowError가 고정된 크기의 JVM 스택에서 프로그램 실행 중 메모리 크기가 충분하지 않았을 때 발생하게 되는 에러이다.
PC(Program Counter) Register
특정 메서드의 작업을 수행하는 각 JVM 스레드에는 이와 연관된 PC 레지스터가 있다.
PC 레지스터에는 현재 스레드가 실행되는 부분의 주소와 명령을 저장하고 있다.
cpu 레지스터랑은 다르다.
Native Method Stack
네이티브 메서드 스택 영역은 C 스택이라고도 하는 기본 메서드 스택을 사용하며 자바 이외의 언어로 작성된 네이티브 코드를 실행할 때 사용되는 메모리 영역이다.
보통 C/C++ 등의 코드를 수행하기 위한 스택을 말하며 JNI 자바 컴파일러에 의해 변환된 자바 바이트 코드를 읽고 해석하는 역할을 하는 것이 자바 인터프리터이다.
실행 엔진(Execution Engine)
실행 엔진은 클래스 로더(Class Loader)를 통해 런타임 데이터 영역(Runtime Data Areas)에 배치된 바이트 코드를 명령어 단위로 읽어서 실행한다.
자바 바이트 코드(*.class)는 기계가 바로 수행할 수 있는 언어보다는 가상 머신이 이해할 수 있는 중간 레벨로 컴파일된 코드이기 때문에 실행 엔진은 이와 같은 바이트 코드를 실제로 JVM 내부에서 기계가 실행할 수 있는 형태로 변경해 준다.
이러한 수행 과정에서 실행 엔진은 인터프리터와 JIT 컴파일러 두 가지 방식을 혼합하여 바이트 코드를 실행한다.
인터프리터(Interpreter)
바이트 코드 명령어를 하나씩 읽어서 해석하고 바로 실행한다.
JVM안에서 바이트코드는 기본적으로 인터프리터 방식으로 동작한다.
같은 메서드라도 여러 번 호출이 된다면 매번 해석하고 수행해야 돼서 전체적인 속도는 느리다.
JIT 컴파일러(Just-In-Time Compiler)
인터프리터의 단점을 보완하기 위해 도입된 방식으로 반복되는 코드를 발견하여 바이트 코드 전체를 컴파일하여 네이티브 코드로 변경하고 이후 해당 메서드를 더 이상 인터프리팅하지 않고 캐싱해 두었다가 네이티브 코드로 직접 실행하는 방식이다.
전체적인 실행 속도는 인터프리터 방식보다 빠르다.
하지만 바이트코드를 네이티브 코드로 변환하는 데 비용이 소모되므로 JVM은 바이트코드를 인터프리터 방식으로 처리하다가 일정 기준이 넘어가면 JIT 컴파일 방식으로 명령어를 실행하게 된다.
가비지 컬렉터(Garbage Collector, GC)
JVM은 가비지 컬렉터(GC)를 이용해서 Heap 메모리 영역에서 더는 사용하지 않는 메모리를 자동으로 회수해 준다.
C언어에서는 개발자가 수동으로 메모리를 할당 및 해제해야 되지만 자바는 가비지 컬렉터를 이용해서 자동으로 메모리를 실시간 최적하 시켜준다.
일반적으로 자동으로 실행되지만 따로 GC가 실행되는 시간이 정해져 있지는 않다.
Full GC가 발생하는 경우 GC를 제외한 모든 스레드가 중지되기 때문에 장애가 발생할 수 있다.
참고 자료
☕ JVM 내부 구조 & 메모리 영역 💯 총정리
저번 포스팅에서는 JRE / JDK / JVM에 대해서 간략하게 알아보는 시간을 가졌다면, 이번 포스팅에서는 JVM의 내부 구조에 대해 좀 더 자세하게 알아보도록 할 예정이다. JVM(자바 가상 머신)은 자바 언
inpa.tistory.com
How many types of memory areas are allocated by JVM? - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
[Java] 자바 JVM 내부 구조와 메모리 구조에 대하여
저번 포스팅에서는 JVM에 대해서 간략하게 알아보는 시간을 가졌다면 이번 포스팅에서는 JVM의 내부 구조에 대해 좀 더 자세하게 알아보도록 하겠습니다. 혹시 JVM의 정의와 왜 필요한지 궁금하시
coding-factory.tistory.com
'자바' 카테고리의 다른 글
| [Java] - Mutable vs Immutable (0) | 2024.09.09 |
|---|---|
| [Java] - GC(Garbage Collection) (1) | 2024.08.29 |
| [Java] - 스레드 (1) | 2023.11.29 |
| [Java] - 입출력 스트림 (0) | 2023.11.29 |
| [Java] - JDK? JVM? JRE? 이게 다 무슨 소리지? (0) | 2023.11.26 |